
java
jvm
jvm内存区域
程序计数器、堆、栈、本地方法栈、方法区
jvm多线程并发创建对象解决方案
- cas+失败重试
- 每个线程留出一块内存:本地线程分配缓存(Thread Local Allocation Buffer - TLAB)
内存回收(gc) - 方法论
垃圾收集算法 对应垃圾收集算法 分代
- 标记 - 清除 CMS 年老代
- 标记 - 复制 ParNew Serial 年轻代
- 标记 - 整理 G1(整体) Serial-Old 年老代
内存回收(gc)如何发起
GC Roots
内存回收(gc)如何加速
记忆集与卡表 - 解决跨代引用
写屏障 - 解决卡表数据中引用类型字段何时更新的问题
内存回收如何正确
增量更新
原始快照
内存回收(gc) - 实践者
垃圾收集器,代表有 CMS,G1
垃圾收集器日志
P123
故障处理工具
内置
命令行:jps jinfo jstack jstat jmap
jinfo: jvm的配置信息
jstack: 查看线程信息
jstat: 统计gc,class loader信息等1
2
3
4
5
6
7
8
9
10
11-gc:统计 jdk gc时 heap信息,以使用空间字节数表示
-gcutil:统计 gc时, heap情况,以使用空间的百分比表示
-class:统计 class loader行为信息
-compile:统计编译行为信息
-gccapacity:统计不同 generations(新生代,老年代,持久代)的 heap容量情况
-gccause:统计引起 gc的事件
-gcnew:统计 gc时,新生代的情况
-gcnewcapacity:统计 gc时,新生代 heap容量
-gcold:统计 gc时,老年代的情况
-gcoldcapacity:统计 gc时,老年代 heap容量
-gcpermcapacity:统计 gc时, permanent区 heap容量
可视化:jconsole jhsdb
外置
可视化:jmc visualVM mat(eclipse memory analyzer) HeapAnalyer
内存回收(gc) 发生的场景和java命令查看oom的方法
总结起来是四个区域:堆,栈,matespace,堆外
https://cloud.tencent.com/developer/article/1730910
https://xie.infoq.cn/article/74d7449272c21dd9f8d706957
jvm oom 后服务还能运行吗
OOM异常会导致JVM退出吗?
JVM内存溢出后服务还能运行吗
OOM会不会导致JVM崩溃
OOM 后我如何分析解决的原创
class loader(类加载)
类加载过程
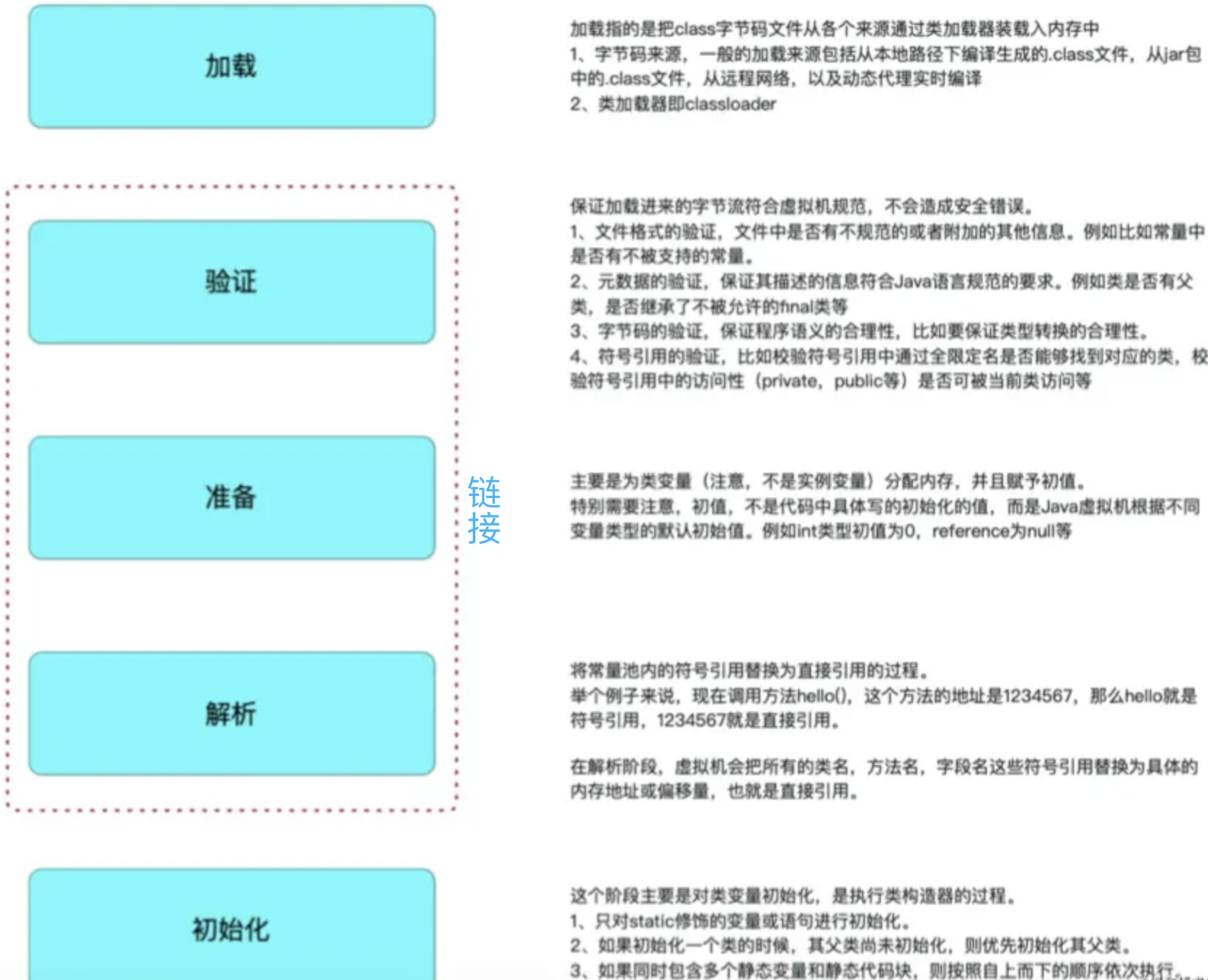
参考:https://juejin.cn/post/6931972267609948167#comment
双亲委派机制
哪些组件破坏了双亲委派机制
1 | jdbc tomcat spring破坏了双亲委派机制 |
https://juejin.cn/post/6916314841472991239
对象内存布局 and CAS
https://www.bilibili.com/video/BV1xK4y1C7aT?p=3&spm_id_from=pageDriver
compressed class pointer
https://www.bilibili.com/video/BV1xK4y1C7aT?p=3&spm_id_from=pageDriver
https://stuefe.de/posts/metaspace/what-is-compressed-class-space/
Java8 新特性教程
HotSpot
Removal of PermGen.
Java 编程语言
1 | Lambda 表达式是一个新的语言特性 |
Date API(日期相关API)
集合
1 | 针对存在键冲突的 HashMap 的性能改进 |
Concurrency
1 | Classes and interfaces have been added to the java.util.concurrent package. |
Tools
1 | The jjs command is provided to invoke the Nashorn engine. |
https://www.oracle.com/cn/java/technologies/javase/8-whats-new.html
https://www.oracle.com/java/technologies/javase/8-whats-new.html
volatile 可见性和禁止指令重排
- volatile 可见性
volatile 可见性在 cpu层面是通过缓存一致性协议实现的。缓存一致性协议简单说:一个 cpu 改了某一个缓存行的变量值,其他的 cpu 想读这个变量值,必须先刷新缓存行后(从主存更新),再读取
缓存行 (Cache Line) 是 CPU Cache 中的最小单位,一个缓存行的大小通常是 64 字节(这取决于 CPU),并且它有效地引用主内存中的一块地址。一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。
cpu级的数据一致性是以cache line为单位的
P5 4-内存屏障的基本概念 38分钟:缓存行 缓存一致性协议 60分钟:乱序执行
- volatile 禁止指令重排
DCL(double check lock)需不需要volatile? 答案:需要,new一个对象时使用三条指令,指令二和指令三重排序了,导致用户会使用半初始化的对象
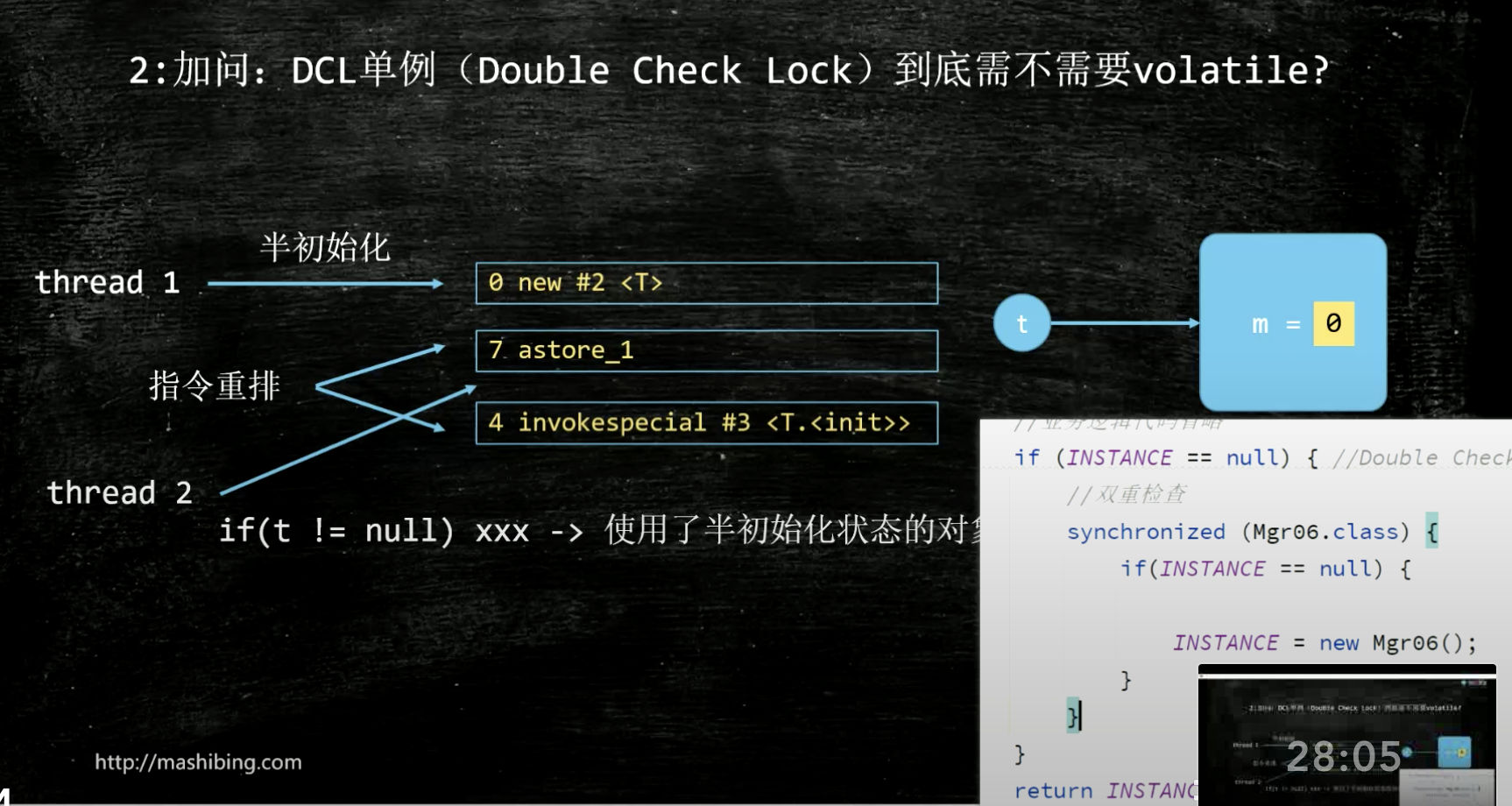
volatile如何应用到singlten单例模式中-7分钟
解决指令重排的方案:变量加volatile来禁止指令重排。
那么问题又来了,volatile是怎么做到禁止指令重排的呢。
答案是:JSR内存屏障。当volatile修饰一个对象时,new前后加了xxBarrier。 NOTE: 这是一个规范,实际上jvm不是这么实现的,实际是通过 lock 实现的(通过hotspot源码的bytecodeinterpreter.cpp可以看到)

- 总结:jvm 层面是用的是屏障xxBarrier,而 cpu 层面用的是缓存行 cache line。
两者的关系:
volatile用于解决缓存一致性问题,因为volatile实际上只是保证了对CPU缓存的操作立即flush到内存,此时的flush依然是以缓存行为单位的,也即你对某缓存行中的单个变量的volatile实际上是应用到了整个缓存行的所有变量,进而会有不同变量的不必要的操作同步,影响性能,此时便需要解决这个问题。
volatile在jvm中的实现代码 bytecodeinterpreter.cpp
https://www.bilibili.com/video/BV1xK4y1C7aT?p=7 13分钟
java锁
sychronized
sychronized原理,字节码层级的支持entermonitor exitmonitor; 编译层级的支持lock cmpxchg指令
https://www.bilibili.com/video/BV1xK4y1C7aT?p=5&spm_id_from=pageDriver 14分钟
sychronized锁升级过程
- 锁升级五个阶段:无锁 偏向锁 轻量级锁 自旋锁 重量级锁
1
2
3
4
5
6
7
8
9
10每一个线程在准备获取共享资源时都会执行如下逻辑:
当线程进入同步代码块时,
第零步,这时是无锁状态,
第一步,此时,线程会检查 MarkWord 里面是否存放有自己的 ThreadId ,如果是,标识位置为 01 ,表示当前线程是处于 “偏向锁”;
第二步,如果 MarkWord 不是自己的 ThreadId ,进行锁升级。此时,此线程根据 MarkWord 里面现有的 ThreadId ,通知该线程暂停,
该线程将 Markword 的内容置为空。然后,两个线程都想获得锁,
第三步,两个线程会在自己的栈帧中建立一个 Lock Record 的空间,两个线程都会通过 CAS 方式尝试将自己的 Mark Word 更新为指向自己栈的 LockRecord 的指针;
第四步,第三步中成功执行 CAS 的获得资源的线程获取到锁,将标识位置为 00 ;失败的线程则进入自旋;
第五步,自旋的线程在自旋过程中,成功获得资源(即之前获的资源的线程执行完成并释放了共享资源),则整个状态依然处于 轻量级锁的状态,如果自旋失败
第六步,进入重量级锁的状态,这个时候,自旋的线程进行阻塞,等待之前线程执行完成并唤醒自己

锁升级是什么时候发生的?
偏向锁:一个线程获取锁时会由无锁升级为偏向锁
自旋锁:当产生线程竞争时由偏向锁升级为自旋锁,想象一下 while(true) ;
重量级锁:当线程竞争到达一定数量或超过一定时间时,晋升为重量级锁锁升级代码实践
sychronized有锁升级,那么有锁降级吗?
锁降级如果是指:sychronized的锁降级,那么是没有的;但是锁降级如果指的是读写锁(ReentantReadWriteLock)的降级,那么是有的。指的是写锁降级为读锁的过程。详见ReentantReadWriteLock的部分
Lock
ReentantLock
Reentantlock的实现原理
线程1来了,尝试获取锁,如果cas成功,获取锁成功,返回;如果获取锁失败,排队等待。在哪排队:一个队列。如何排队,
Condition实现原理
ReentantReadWriteLock
ReentantReadWriteLock的实现原理
ReentantReadWriteLock使用实例
ReentantReadWriteLock锁降级
锁降级发生在读写锁中,写锁降级读锁的过程。
1 | 问:为什么可以锁降级,也就是说,为什么释放写锁之前可以获取读锁? |
synchronized和Lock对比
Lock相较于Synchronized优势
1 | 如下: |
Lock vs Synchronized分别适用什么样的场景
Lock vs Synchronized知识整体参考:
Java锁的那些事儿
Synchronized和 ReentrantLock到底怎么选,我蒙了
AQS
AQS 内部的关键是什么
1 | AQS的核心:一个双向队列(双向的FIFO) 和一个同步状态(0:可用,1:被占用) |
自总结学习AQS步骤
- 看大牛的文章
- debug源码 使用合适的demo小例子很重要
- 看看开源组件如何使用的AQS
- 自己找场景使用
带着疑问debug
- FIFO队列中的head这个虚节点waitStatus的值是什么
- FIFO队列中的node节点的waitStatus的值,在节点加入队列时是什么,然后又会在什么时候更新
答案的核心都在这两个方法中: acquireQueued (addWaiter(Node.EXCLUSIVE), arg)
节点在加到队列时的waitStatus值都是0,此操作在addWaiter(Node.EXCLUSIVE) 方法中。而节点的状态的更新在 acquireQueued(node, arg) 方法中。node节点是包含当前线程的节点,addWaiter将node放入队列。随后 acquireQueued 方法会看看队列中的此节点能否获取到锁,不能获取时就会更新此节点的waitStatus的值。具体在 acquireQueued 方法中的 shouldParkAfterFailedAcquire(p, node) 方法。
注意:
1.参数中的 p 是 node 的前继节点,即 p = node.pre。
2.shouldParkAfterFailedAcquire 改的是 p 节点的waitStatus 值。从0更新到SIGNAL(-1)。然后,node 节点的线程就会通过 parkAndCheckInterrupt() 方法 LockSupport.park(this) 挂起了。那么问题又来了,它啥时候会被唤醒呢。
小结下:此时 node 节点的 waitStatus 值还是0,而 p(p = node.pre) 节点的 waitStatus 值为 SIGNAL(-1)。
【深入AQS原理】我画了35张图就是为了让你深入 AQS
一行一行源码分析清楚 AbstractQueuedSynchronizer
BlockingQueue
LinkedBlockingQueue
HashMap
属性值的含义
1 | 初始值 16的原因:1,必须是2的幂次,这时候 (n - 1) & hash 等价于 n%hash,与运算(&)比取余(%)运算效率高,与运更高效。算散列最均匀;如果太小,4或者8,扩容比较频繁;如果太大,32或者64甚至太大,又占用内存空间 |
面试加分项-HashMap源码中这些常量的设计目的
hashmap的泊松分布,二项式分布?
HashMap多线程下不安全的原因
- java8以前的版本
rehash时可能出现链表成环
疫苗:JAVA HASHMAP的死循环
为什么HashMap线程不安全?
- java8的版本
因为 JDK1.8 已经修复了rehash时可能出现链表成环的问题,但是依然不建议在多线程环境下使用 HashMap!
ConcurrentHashMap
ConcurrentHashMap是如何做到线程安全的,他的数据结构是什么
java8下,数据结构和HashMap一样。做到线程安全的的办法是通过 CAS + synchronized
ConcurrentHashMap 中 synchronized 只锁定当前链表或红黑二叉树的首节点,只要节点 hash 不冲突,就不会产生并发,相比 JDK1.7 的 ConcurrentHashMap 效率又提升了 N 倍!
面试必问之 ConcurrentHashMap 线程安全的具体实现方式
ConcurrentHashMap真的安全吗?
https://developer.aliyun.com/article/776568
threadLocal
https://www.bilibili.com/video/BV1fA411b7SX/ 46分钟
https://www.bilibili.com/video/BV1xK4y1C7aT?p=8 20分钟
万字图文深度解析ThreadLocal
-> Question:
C. threadLocalMap 的key为啥是threadLocal对象呢,用threadId可以吗
E. 为什么ThreadLocalMap 如何解决hash碰撞的呢:采用(线性探测法)开放地址法来解决哈希冲突? 为啥不用hashmap的链表法
D. threadLocal 的魔数0x61c88647的原理
B. threadLocalMap 的 Entry 对象为啥是弱引用的呢
F. threadLocal 会发生内存泄漏吗
H. 代码实践查看gc 后Entry的key 和value是否被回收
M. threadLocal 过期key的清理机制是什么?探测(触发)式清理:replaceStaleEntry;启发式清理:cleanSomeSlots
N. threadLocal缺点,InheritableThreadLocal是什么,TransmittableThreadLocal是什么
threadLocal缺点是不能在线程间传递数据,InheritableThreadLocal可以在父子线程间传递数据,TransmittableThreadLocal可以在线程池中的线程间传递数据,是Alibaba开源的
G. ThreadLocalMap 和 HashMap 的区别
- HashMap 的数据结构是数组+链表,而ThreadLocalMap的数据结构仅仅是数组
- HashMap 是通过链地址法解决hash 冲突的问题,而ThreadLocalMap 是通过开放地址法来解决hash 冲突的问题
- HashMap 里面的Entry 内部类的引用都是强引用,而ThreadLocalMap里面的Entry 内部类中的key 是弱引用,value 是强引用
-> Answer Question:
C. threadLocalMap 的key为啥是threadLocal对象呢,用threadId可以吗
使用threadId无法区分一个线程多个threadLocal的情况
E. 为什么ThreadLocalMap 采用(线性探测法)开放地址法来解决哈希冲突,为啥不用 Hashmap 的链表法
1 | ThreadLocalMap 采用开放地址法(线性探测法)原因 |
被大厂面试官连环炮轰炸的ThreadLocal(吃透源码的每一个细节和设计原理)
D. threadLocal 的魔数0x61c88647
0x61c88647 的二进制为:1100001110010001000011001000111
0x61c88647 的十进制为:1640531527
1 | HASH_INCREMENT = 0x61c88647; 目的是使:ThreadLocal对象的threadLocalHashCode较为均匀地分布在2的幂大小的数组中。 |
B. threadLocalMap 的Entry对象为啥是弱引用的呢
是出于 GC 考虑,当某个 ThreadLocal 已经没有强引用指向时,它被 GC 回收,那么ThreadLocalMap 里对应的 Entry 的键值会随之失效
如果key是强引用,即使tl=null,但key的引用依然指向ThreadLocal对象,所以会造成内存泄漏,而使用弱引用则不会。
F. threadLocal 会发生内存泄漏吗
ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用引用他,那么系统gc的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value。永远无法回收,造成内存泄露。
一个具体的例子就是:如果线程是线程池的, 在线程执行完代码的时候并没有结束,只是归还给线程池,这个时候ThreadLocalMap 和里面的元素是不会回收掉的,尤其value是大对象时,就会容易造成内存泄露。
从图中可以容易理解下
1.堆栈角度的对象引用图
2.线程角度的对象引用图
H. 代码实践查看gc 后Entry的key 和value是否被回收
1 | https://segmentfault.com/a/1190000022663697 的反射部分 |
M. threadLocal 过期key的清理机制是什么?探测(触发)式清理:replaceStaleEntry;启发式清理:cleanSomeSlots
探测式清理是以当前Entry 往后清理,遇到值为null则结束清理,属于线性探测清理。之前发生 Hash冲突 的Entry元素的位置应该更接近真实hash出来的位置。提升了查找的效率。这里探测式清理并不能全部清除数组中的过期元素,而是从传入的下标清理到第一个 Entry==null 为止。部分清除。
其余的部分,需要通过 启发式清理
启动式清理会从传入的下标 i 处,向后遍历。如果发现过期的Entry则再次触发探测式清理,并重置 n
G. ThreadLocalMap和 HashMap的区别。ThreadLocalMap 和HashMap的功能类似,但是实现上却有很大的不同:
1 | 1. 数据结构 |
线程安全的队列
如果我们要实现一个线程安全的队列有两种实现方式一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现,而非阻塞的实现方式则可以使用循环CAS的方式来实现
ConcurrentLinkedQueue
…
LinkedBlockingQueue
…
threadpoolExecutor 线程池
线程池的执行流程
done
线程池核心线程何时销毁
当缓存队列中的任务都执行完了的时候,线程池中的线程数如果大于核心线程数,就销毁多出来的线程,直到线程池中的线程数等于核心线程数。此时这些线程就不会被销毁了,它们一直处于阻塞状态,等待新的任务到来。
详细参见:线程池是如何重复利用空闲线程的
几个核心问题
线程池的核心线程是如何保持一直在的
在 runWorker 方法中,再进入 getTask() 方法中,如果没有任务,队列就会阻塞。从而达到线程不回收,即保持一直存活着的。这也是为啥用阻塞队列的原因。可能你会说,用for自循环也可以实现,对的,但那样会一直占用CPU资源线程池中的线程是如何重用的
答案在 runWorker 方法中
线程之所以能达到复用,就是在当前线程执行的runWorker方法中有个while循环,while循环的第一个判断条件是执行当前线程关联的Worker对象中的任务,执行一轮后进入while循环的第二个判断条件getTask(),从任务队列中取任务,取这个任务的过程要么是一直阻塞的,要么是阻塞一定时间直到超时才结束的,超时到了的时候这个线程也就走到了生命的尽头。
然而在我们开始分析execute的时候,这个方法中的三个部分都会调用addWorker去执行任务,在addWorker方法中都会去新建一个线程来执行任务,这样的话是不是每次execute都是去创建线程了?事实上,复用机制跟线程池的阻塞队列有很大关系,我们可以看到,在execute在核心线程满了,但是队列不满的时候会把任务加入到队列中,一旦加入成功,之前被阻塞的线程就会被唤醒去执行新的任务,这样就不会重新创建线程了。
详细参见:线程池是如何重复利用空闲线程的
线程池使用注意事项
- 一般建议是不同的业务使用不同的线程池,线程池间独立使用
- 正确配置线程池参数
- 别忘记给线程池命名
线程池设置多少合适呢
- cpu密集型的设置多少,io密集型的设置多少
- ❶ CPU密集型程序: CPU 核数(逻辑)+ 1 个线程数。
计算密集型的任务,通常很需要CPU资源。如果线程太多,就需要太多的上下文切换,上下文切换会很浪费CPU资源,降低了线程的执行时间。所以,对于计算密集型的任务,线程池核心线程数为:CPU 核数(逻辑)+ 1 个线程数。
CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1。比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
❷ I/O 密集型程序: 2N
I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。❸ 最佳线程数 = CPU核心数(1/CPU利用率) = CPU核心数(IO耗时/CPU耗时)
❹ 我怎么知道具体的 I/O耗时和CPU耗时呢?怎么查看CPU利用率?
APM(SkyWalking CAT zipkin)工具或者JDK自带的工具 VisualVM可以帮我们得到准确的数据,学会使用这类工具,也就可以结合理论,在调优的过程得到更优的线程个数了。
Tips 具体的要结合机器是多少核心的,机器上有多少个服务,这些服务已占用了多少线程数。再加上本服务执行的任务类型,再通过APM查看具体的数值
关于线程池胡思乱想产生的问题
todo
- 线程池中线程是如何回收的呢,假设现在任务已经用了最大线程数执行完了,队列里的任务也执行完了。按按照线程池的约定(假设核心线程不允许超时),线程池会回收除了核心线程以外的线程。它是如何回收的呢
- 答案:此逻辑在
runWorker和getTask方法中。具体为:每个worker执行完firstTask后,会从队列中拿任务,这个队列是阻塞队列,如果此时线程池线程数大于corePoolSize,那么阻塞队列获取任务用的是workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)方法,当在指定时间没有拿到任务就返回null,runWorker方法拿到null就会退出while循环,runWorker方法在结束前执行workers.remove(w),从集合中删除,然后runWorker方法所在的线程就结束了,线程池中自然就减少了一个线程。
- 线程池中的任务是如何运行的。
- 答案:当一个任务通过execute方法放入线程池,在new Worker时会将Worker与Thread产生关联。
this.thread = getThreadFactory().newThread(this);,相当于thread.runable = worker,所以,addWorker方法中执行 thread.start()方法时,会执行runable.run方法,即worker.run方法,1
2
3
4
5public void run() {
runWorker(this);
}
this=worker,runWorker(worker)里会取到worker.firstTask。firstTask即是我们最开始的任务: firstTask.run()
线程池运用不当导致的问题的实例
redis - Redis 远程字典服务器 (Remote Dictionary Server)
why is redis so fast
Redis The data is in memory , All operations are memory level operations. Redis is a RAM-based data store. RAM access is at least 1000 times faster than random disk access.
Redis It’s single threaded, The loss caused by thread switching and locking is avoided.
Redis leverages IO multiplexing and single-threaded execution loop for execution efficiency,IO Multiplexer listens for multiple socket, And will socket Put in queue, One at a time from the queue socket To event dispatcher, The event dispatcher then socket Assign to the corresponding event processor for processing, These processors are pure memory operations, Very efficient, Processing an event may take only a few microseconds.
Redis data structure
Redis There is a file event handler inside, It is single threaded, It consists of four parts, namely :IO Multiplex program,socket, Event dispatcher and event handler, The event processor is divided into:Connect reply processor, Command request processor and command reply processor.
详情:
Redis Why fast
IO Multiplexing
IO 多路复用
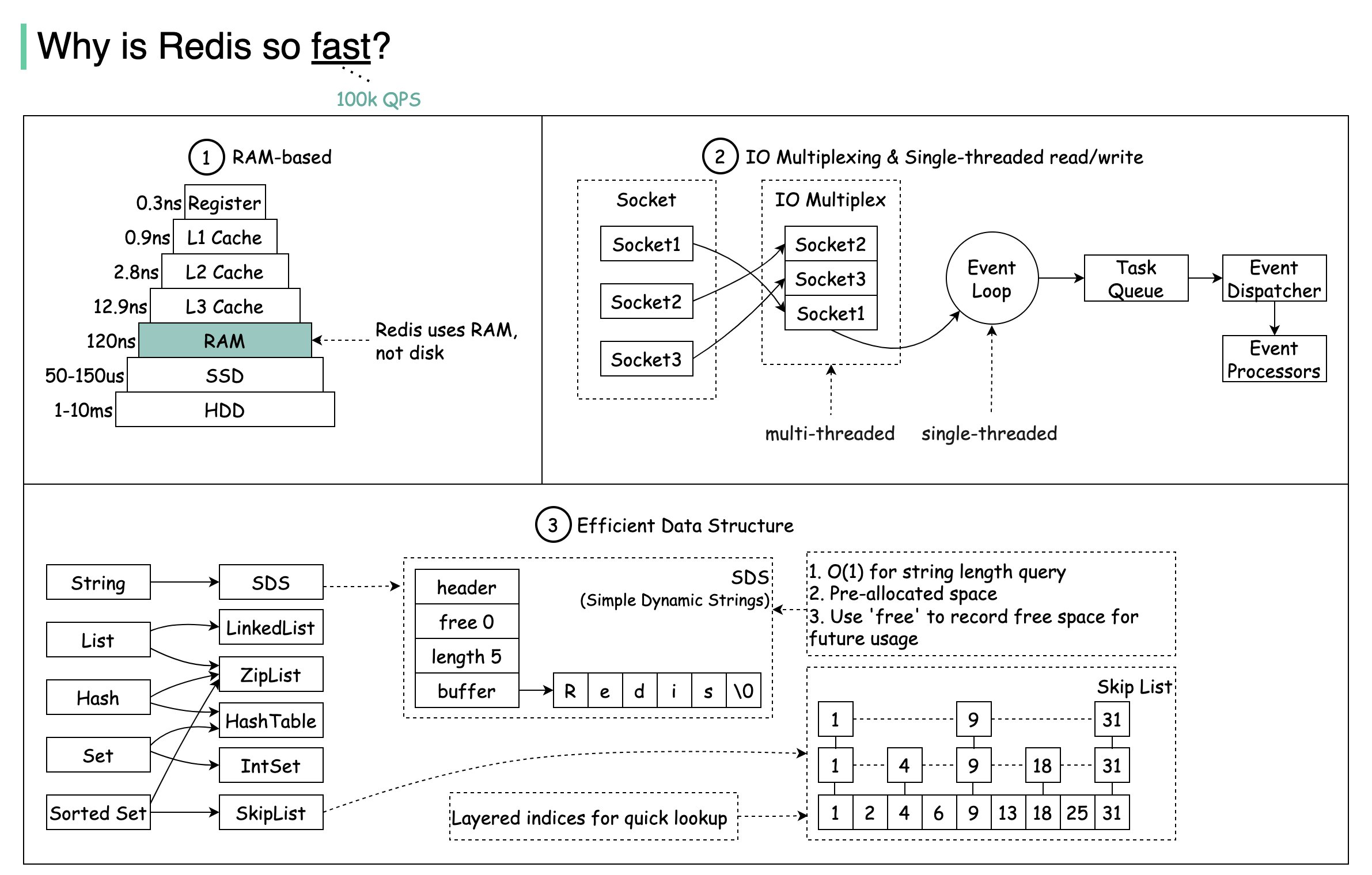
redis 线程模型
redis缓存穿透,缓存击穿,缓存雪崩 布隆过滤器
https://www.bilibili.com/video/BV1Yk4y1y76r?p=101&spm_id_from=pageDriver
https://yaoyuanyy.github.io/2022/05/15/interview%E5%A4%A7%E5%8E%82%E9%9D%A2%E8%AF%95%E7%9C%9F%E9%A2%98%E8%8D%89%E5%BD%95/ redis 缓存穿透,缓存击穿,缓存雪崩及解决方案
redis 分布式锁
锁的核心:互斥
redis 分布式锁的实现原理 setnx的弊端 redis分布式锁的过期时间设置方法
1. 上锁的问题
setnx的弊端:设置锁和超时时间不是原子操作
SETNX lock:168 1 // 获取锁
(integer) 1
EXPIRE lock:168 60 // 60s 自动删除
方案:
2.6版本:SET resource_name random_value NX PX 30000
2. 解锁的问题
- 释放了不是自己加的锁
1 | 客户 1 获取锁成功并设置设置 30 秒超时; |
方案:加锁时设置唯一标识(如随机数),解锁时get 值与唯一标识判等1
2
3if (redis.get("lock:168").equals(random_value)){
redis.del("lock:168"); //比对成功则删除
}
- 依然有问题 - get del 不是原子操作
方案:lua脚本
3. 超时时间的问题 - 锁的超时时间怎么计算合适呢?
设置短了,如发生网络io,fullgc,锁就失效了;设置成了,如果宕机,再回来,服务无法再获得锁
方案:redisson watchdog自动续期
我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁「续航」。
加锁的时候设置一个过期时间,同时客户端开启一个「守护线程」,定时去检测这个锁的失效时间。
如果快要过期,但是业务逻辑还没执行完成,自动对这个锁进行续期,重新设置过期时间。
4. 加解锁代码位置问题
加解锁代码位置有讲究
1 | public void doSomething() { |
加锁代码放(1)处的问题:lock方法里如果没有加锁成功服务异常了,解锁时会释放没有加锁的锁
释放锁这个问题比较明显了,不说了
5. 主从架构带来锁的问题
具体的问题场景:主从下master宕机,slave还没有master上的key,造成重复获取锁。
本质是redis集群数据同步机制
由于 Redis 集群数据同步到各个节点时是异步的,如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
以上详情阅读:Redis 分布式锁的正确实现原理演化历程与 Redission 实战总结
redis key的过期策略
关键词:
集中删除(定时删除) + 惰性删除(访问key时删除)
集中删除:redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,有个定时器,会定时遍历这个字典来删除到期的 key。
惰性删除:在客户端访问这个 key 的时候,redis 对 key 的过期时间进行检查,如果过期了就立即删除。
定时删除是集中处理,惰性删除是零散处理。
redis 内存淘汰策略 Key eviction (it`s policies is LRU, LFU, etc.)
关键词:
为啥淘汰:超过maxmemory
何时淘汰:add key/value时,redis检查如果发现超过maxmemory
咋样淘汰:根据淘汰策略 evicts keys,类似 LRU,LFU
LRU算法 - 突出访问的先后(顺序)
LRU(Least Recently Used)最近最少使用(最近最久未使用)。优先淘汰最近未被使用的数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
LRU底层结构是 hash 表 + 双向链表。hash 表用于保证查询操作的时间复杂度是O(1),双向链表用于保证节点插入、节点删除的时间复杂度是O(1)。
为什么是 双向链表而不是单链表呢?单链表可以实现头部插入新节点、尾部删除旧节点的时间复杂度都是O(1),但是对于中间节点时间复杂度是O(n),因为对于中间节点c,我们需要将该节点c移动到头部,此时只知道他的下一个节点,要知道其上一个节点需要遍历整个链表,时间复杂度为O(n)。
注意:redis使用的是近似LRU,为啥呢?
LRU算法源码可参考Leetcode:https://www.programcreek.com/2013/03/leetcode-lru-cache-java/
玩转Redis:8种数据淘汰策略及近似LRU、LFU原理 - LRU部分
LFU算法 - 突出访问的次数(频率)
LFU:Least Frequently Used,最近使用频率最少的(最不频繁使用的)
LFU 使用 Morris counter 概率计数器,仅使用几比特就可以维护 访问频率,Morris算法利用随机算法来增加计数,在 Morris 算法中,计数不是真实的计数,它代表的是实际计数的量级。
优先淘汰最近使用的少的数据,其核心思想是“如果一个数据在最近一段时间很少被访问到,那么将来被访问的可能性也很小
玩转Redis:8种数据淘汰策略及近似LRU、LFU原理 - LFU部分
redis bigKey问题
What bigKey 是什么
有什么影响(危害)
1
2
3
4
51.内存空间的影响:redis集群一般是单机多实例部署,所以会导致内存空间不均衡,影响整个集群。
2.请求阻塞的影响:redis操作大key非常耗时,属于慢查询,执行时间过长时,会阻塞其他客户端。因为 Redis 单线程特性,如果操作某个 Bigkey 耗时比较久,则后面的请求会被阻塞。
3.网卡流量的影响:当大key例如12MB时,如果这个key每秒访问量是100的话,每秒产生流量为1200MB,对于普通服务器一般是扛不住这么大的流量的。
4.bigkey過期刪除時造成命令阻塞 Redis 4.0通过异步命令解决
5.数据倾斜:一个实例数据特别多,其他的相对少Why 产生的原因是什么
一般來說,bigkey的產生都是由於程序設計不當。沒有對Key中的成員進行合理的拆分,造成個別Key中的成員數量過多(大Key)。如何发现 bigKey
工具How 解决的办法是什么
1 | 1.拆分大key。 |
redis hotKey问题
What hotKey 是什么
有什么影响(危害)
1 | 1. 流量集中,达到服务器处理上限(CPU、网络 IO 等); |
- Why 产生的原因是什么
预期外的访问量陡增,如突然出现的爆款商品、访问量暴涨的热点新闻、主播搞活动带来的大量刷屏点赞等
如何发现 hotKey
1
2
3
4客户端收集上报
代理层收集上报
Redis 数据定时扫描hotkeys 查找特性,可以直接利用 redis-cli --hotkeys 获取当前 keyspace 的热点 key,实现上是通过 scan + object freq 完成的
Redis 节点抓包解析How 解决的办法是什么
1
2
3增加 Redis 实例复本数量: 分担读流量
热 Key 备份: 比如key,备份为key1,key2……keyN,同样的数据N个备份,N个备份分布到不同分片,访问时可随机访问N个备份中的一个,进一步分担读流量
二级缓存(本地缓存): 使用本地缓存,发现热key后,将热key对应数据加载到应用服务器本地缓存中,访问热key数据时,直接从本地缓存中获取,而不会请求到redis服务器。
Redis 热 Key 发现以及解决办法
谈谈redis的热key问题如何解决
Redis Bigkey or Hotkey issue?
redis zset底层实现原理
skiplist 跳跃表
Redis实现高可用(怎么防止数据丢失)
在 Web 服务器中,高可用 是指服务器可以 正常访问 的时间,衡量的标准是在 多长时间 内可以提供正常服务(99.9%、99.99%、99.999% 等等)。在 Redis 层面,高可用 的含义要宽泛一些,除了保证提供 正常服务(如 主从分离、快速容灾技术 等),还需要考虑 数据容量扩展、数据安全 等等。
主要有以下方面来保证:
1.持久化:
持久化是 最简单的 高可用方法。它的主要作用是 数据备份,即将数据存储在 硬盘,保证数据不会因进程退出而丢失。
2.复制:
复制是高可用 Redis 的基础,哨兵 和 集群 都是在 复制基础 上实现高可用的。复制主要实现了数据的多机备份以及对于读操作的负载均衡和简单的故障恢复。缺陷是故障恢复无法自动化、写操作无法负载均衡、存储能力受到单机的限制。
3.哨兵:
在复制的基础上,哨兵实现了 自动化 的 故障恢复。缺陷是 写操作 无法负载均衡,存储能力受到单机的限制。
4.集群:
通过集群,提高了 写操作 能力,Redis 解决了 写操作 无法负载均衡以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
5.自动故障恢复
- -> 数据持久化 - 高可用的基础
因为Redis的主从复制和自动故障恢复,都需要依赖Redis持久化相关的东西。同时,Redis的数据持久化也可以用来做数据备份,保障数据的安全性。
Redis提供了完善的持久化机制,可以把内存中的数据持久化到磁盘上,以便我们进行备份数据和快速恢复数据。
Redis提供的数据持久化方式主要有2种:
RDB(Redis Database Backup file):产生一个数据快照文件。RDB文件数据是被压缩写入的,因此RDB文件的体积要比整个实例内存要小。实例宕机恢复时,可以很短时间内迅速恢复。但缺点是:由于是某一时刻的数据快照,因此它的数据并不全
AOF(append of file):实时追加命令的日志文件。比RDB保存更完整的数据,降低丢失数据的风险。但缺点是:随着时间增长,AOF文件会越来越大。同时,AOF文件刷盘会增加磁盘IO的负担,可能影响Redis的性能(开启每秒刷盘时)
参考:https://cloud.tencent.com/developer/article/1730906
- -> 主从复制
Redis 的主从复制模式下,一旦主节点由于故障不能提供服务,需要手动将从节点晋升为主节点,同时还要通知客户端更新主节点地址,这种故障处理方式从一定程度上是无法接受的。Redis 2.8 以后提供了 Redis Sentinel 哨兵机制解决这个问题。
主从还有一个好处:读写分离
- -> 哨兵模式
Redis Sentinel 是 Redis 高可用的实现方案。Sentinel 是一个管理多个 Redis 实例的工具,它可以实现对 Redis 的监控、通知、自动故障转移。
Redis 的 主从复制模式 和 Sentinel 高可用架构 的示意图
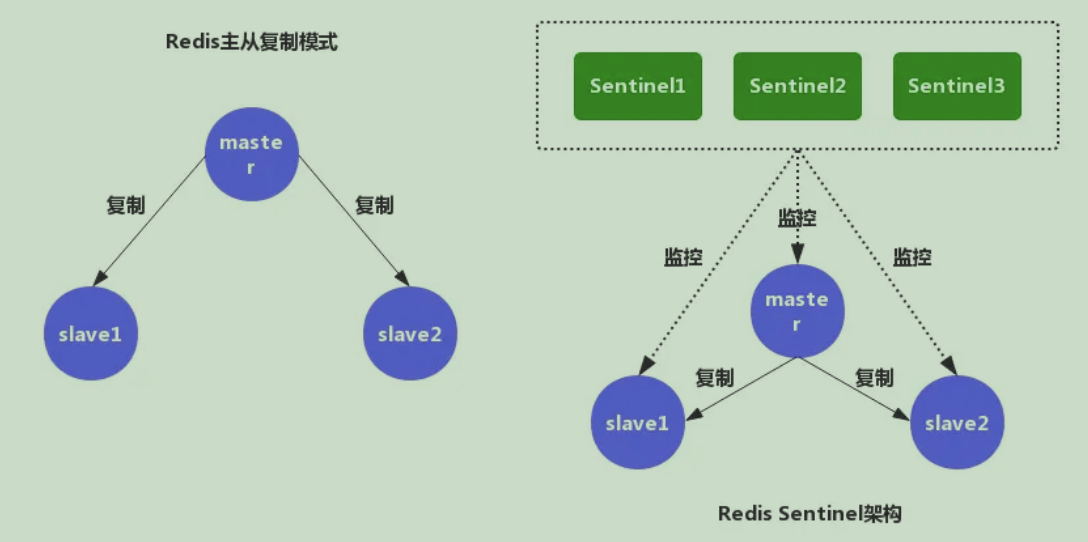
https://juejin.cn/post/6844903663362637832
https://cloud.tencent.com/developer/article/1707625
- -> 集群 redis cluster的原理
Redis主从复制利用主从节点实现读写分离来扩展主节点的数据读取能力,那么当主节点的写入能力成为瓶颈时,集群便是性能扩展的解决方案之一。Redis Cluster是Redis的分布式解决方案
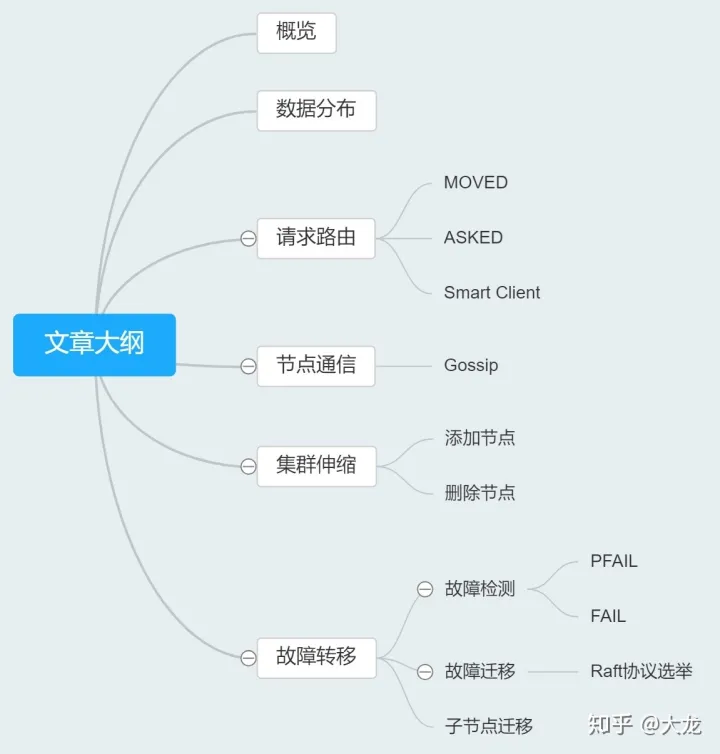
4.1 数据分布策略 - CRC16/16384
Redis采用了虚拟桶分区方法,使用分散度良好地哈希函数把所有的数据均匀地哈希到K个桶中。具体实现中,Redis使用CRC16函数计算键的哈希值并把所有键分到16384个桶中。每个桶只能由一个主节点存储,但一个主节点可以负责多个桶。
4.2 数据查询路由 - MOVED重定向
Redis没有选择使用代理,而是客户端直接连接每个节点。 Redis的每个节点中都存储着整个集群的状态,集群状态中一个重要的信息就是每个桶的负责节点。在具体的实现中,Redis用一个大小固定为CLUSTER_SLOTS的clusterNode数组 slots来保存每个桶的负责节点。
在集群模式下,Redis接收任何键相关命令时首先计算键对应的桶编号,再根据桶找出所对应的节点,如果节点是自身,则处理键命令;否则回复MOVED重定向错误,通知客户端请求正确的节点,这个过程称为MOVED重定向。重定向信息包含了键所对应的桶以及负责该桶的节点地址,根据这些信息客户端就可以向正确的节点发起请求。
4.3 集群节点通信 - Gossip协议
集群中所有节点的状态以及桶-节点映射关系构成集群的元数据。 Redis采用Gossip通信协议来进行集群元数据的同步。 Gossip协议的主要职责就是信息交换。信息交换的载体就是节点彼此发送的Gossip消息。每个Redis都会保存自己视角下的集群中其他节点的状态信息,具体实现中所有的节点信息都存储在clusterNode结构体中。那么使用Gossip协议,集群中的每个节点,每次会随机向几个节点传输自己视角下的集群其他节点状态。如果每次都传输所有的节点状态数据,那么数据体量又会过于庞大,于是Redis集群采用的最终的信息同步方式是: 一个大小为N的集群的每一个节点每次向随机K个其他节点传输自己视角下的随机M个节点的状态。其中M和K都远远小于N。
https://zhuanlan.zhihu.com/p/104641341
4.4 集群伸缩
集群伸缩的核心其实是数据的迁移,而在Redis集群中,数据是以slot为单位的,那么也就是说,Redis集群的伸缩本质上是slot在不同机器节点间的迁移。 同时,要实现扩缩容,我们不仅需要解决数据迁移,我们还需要解决数据路由问题。 比如A节点正在向B节点迁移slot1的数据,在未完成迁移时,slot1中的一部分数据存在节点A上,一部分数据存在节点B上。那么以下三种情况下我们该如何路由slot1的客户端请求?
- 当除了A、B之外的其他节点接收到slot1的数据请求时,其他节点该路由给哪个节点?
- 当节点A接收到slot1的数据请求时,A该自己处理还是路由给B节点?
- 当节点B接收到slot1的数据请求时,B该自己处理还是路由给A节点?
https://zhuanlan.zhihu.com/p/105569485
- -> 自动故障恢复总体介绍
我们在之前提到过,Redis将所有的数据都分到了16384个slots里面同时每个节点负责一部分slots。slot和节点的对应关系是多对一的关系,即每个slot只能被至多一个节点负责存储,每个节点可以负责存储多个slots。所谓的高可用指的是,即使其中一个Master节点下线,整个集群依然能够正常向外提供服务。这是如何做到的呢?简单的来说就是让下线Master节点的Slave节点来成为新的Master节点,接管旧Master负责的所有slots向外提供服务。比如下面的集群拓扑结构,每个Master节点带一个Slave节点。如果M2永久下线之后,那么S2就会替代M2继续向外服务。那么如果替代的S2再次下线后会怎么样呢?显然由于S2不再有Slave节点了,所以S2下线之后整个集群就下线了。为了解决这个问题,Redis还提出一个叫 Replica Migration的解决方案:当集群中的某个Master节点没有Slave节点时(称之为 Orphaned Master),其他有富余Slave节点的主节点会向该节点迁移一个Slave节点以防该节点下线之后没有子节点来替换从而导致整个集群下线。
Redis cluster — 故障自动检测与自动恢复
- 1.故障发现:
如何判定某个Master节点故障了?Redis采用了多数投票的方案。
Redis的每个节点会不停的向其他节点发送PING消息来与其他节点同步信息的同时检测其他节点是否可达。
Redis集群的故障发现也经历两个阶段:PFail和Fail。PFAIL就是主观下线,比如节点1判定节点3下线,那么他会标记节点3的状态为PFAIL。但是如果绝大部分节点都判定节点3为PFAIL,那么我们就可以断定节点3故障下线,其状态判定为FAIL状态。
1).PFAIL:当定超过NODE_TIMEOUT,认为这个节点是PFAIL
2).FAIL:超过一半的节点报告某一节点是PFAIL,那么就判定这个节点FAIL。
3)客观下线状态判定:下线报告列表中超过一半的节点报告某一节点是PFAIL,那么就判定这个节点FAIL。
4).广播信息:判定节点通过 Gossip 广播某一节点的故障消息。当集群中的节点收到此消息时,都会标记节点3的状态为FAIL状态.
- 故障迁移
Redis子节点竞选成为新的Master节点采用了Raft协议
1).资格检查:当一个Slave节点过长时间不与Master节点通信,那么该节点就不具备参与竞选的资格。详情有代码公式
2).休眠时间计算:DELAY = 500 milliseconds + random delay between 0 and 500 milliseconds + SLAVE_RANK * 1000 milliseconds.
3).发起拉票&选举投票:有资格的候选节点向所有的节点(主节点+子节点)都会收到拉票请求,但是只有主节点才具备投票资格
4).节点替换:先标记自己为主节点,然后将原来节点负责的slots标记为由自己负责,最后向整个集群广播现在自己是Master同时负责旧Master所有slots的信息。其他节点接收到该信息后会更新自己维护的这个节点的状态
5).集群配置更新:
- -> Redis 主从复制、哨兵和集群这三个有什么区别
主从复制是为了数据备份和负载均衡,哨兵是为了高可用,Redis主服务器挂了哨兵可以切换,集群则是解决单实例能力有限的问题,将数据按一定的规则分配到多台机器,sentinel着眼于高可用,Cluster提高并发量。
1).主从模式:读写分离,备份,一个Master可以有多个Slaves。
2).哨兵sentinel:监控,自动转移,哨兵发现主服务器挂了后,就会从slave中重新选举一个主服务器。
3).集群:为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,可受益于分布式集群高扩展性。
redis在高并发 高性能的应用
新浪微博开放平台Redis实战
高频面试题
redis如何实现延时队列
Redis 是通过有序集合(ZSet)的方式来实现延迟消息队列的,ZSet 有一个 Score 属性可以用来存储延迟执行的时间。
优点1
2
3
4灵活方便,Redis 是互联网公司的标配,无序额外搭建相关环境;
可进行消息持久化,大大提高了延迟队列的可靠性;
分布式支持,不像 JDK 自身的 DelayQueue;
高可用性,利用 Redis 本身高可用方案,增加了系统健壮性。
缺点1
需要使用无限循环的方式来执行任务检查,会消耗少量的系统资源。
redis集群下一组一个master和两个slave挂了, redis还能提供服务吗
Redis Cluster failure detection is used to recognize when a master or slave node is no longer reachable by the majority of nodes and then respond by promoting a slave to the role of master. When slave promotion is not possible the cluster is put in an error state to stop receiving queries from clients.
Replica migration (复制迁移算)
Redis Cluster实现了一个成为“Replica migration”的概念,用来提升集群的可用性。比如集群中每个master都有一个slave,当集群中有一个master或者slave失效时,而不是master与它的slave同时失效,集群仍然可以继续提供服务。
1)master A,有一个slave A1
2)master A失效,A1被提升为master
3)一段时间后,A1也失效了,那么此时集群中没有其他的slave可以接管服务,集群将不能继续服务。
如果masters与slaves之间的映射关系是固定的(fixed),提高集群抗灾能力的唯一方式,就是给每个master增加更多的slaves,不过这种方式开支很大,需要更多的redis实例。
解决这个问题的方案,我们可以将集群非对称,且在运行时可以动态调整master-slaves的布局(而不是固定master-slaves的映射),比如集群中有三个master A、B、C,它们对应的slave为A1、B1、C1、C2,即C节点有2个slaves。“Replica迁移”可以自动的重新配置slave,将其迁移到某个没有slave的master下。
1)A失效,A1被提升为master
2)此时A1没有任何slave,但是C仍然有2个slave,此时C2被迁移到A1下,成为A1的slave
3)此后某刻,A1失效,那么C2将被提升为master。集群可以继续提供服务。
Replica migration algorithm (复制迁移算法)
迁移算法并没有使用“agree”形式,而是使用一种算法来避免大规模迁移,这个算法确保最终每个master至少有一个slave即可。起初,我们先定义哪个slave是良好的:一个良好的slave不能处于FAIL状态。触发时机为,任何一个slave检测到某个master没有一个良好slave时。参与迁移的slave必须为,持有最多slaves的master的其中一个slave,且不处于FAIL状态,且持有最小的node ID。
比如有10个masters都持有一个slave,有2个masters各持有5个slaves,那么迁移将会发生在持有5个slaves的masters中,且node ID最小的slave node上。我们不再使用“agreement”,不过也有可能当集群的配置不够稳定时,有一种竞争情况的发生,即多个slaves都认为它们自己的ID最小;如果这种情况发生,结果就是可能多个slaves会迁移到同一个master下,不过这并没有什么害处,但是最坏的结果是导致原来的master迁出了所有的slaves,让自己变得单一。但是迁移算法(进程)会在迁移完毕之后重新判断,如果尚未平衡,那么将会重新迁移。
最终,每个master最少持有一个slave;这个算法由用户配置的“cluster-migration-barrier”,此配置参数表示一个master至少保留多少个slaves,其他多余的slaves可以被迁出。此值通常为1,如果设置为2,表示一个master持有的slaves个数大于2时,多余的slaves才可以迁移到持有更少slaves的master下。
复制迁移算法
Redis Cluster实现原理 - 复制迁移
redis cluster的原理
见上文
redis hotkey如何解决,超高的qps 写操作
hotkey如何解决
参考上文超高的qps 写操作
使用pipeline,相当于组成批量请求,然后再发送到redis服务器
redis 高并发写操作
问题描述
先说下为什么redis会存在并发问题,redis不是单线程吗,不管你多少个请求过来,我就只有一个线程,它怎么会有线程安全问题呢?讲道理永远不会出现并发问题;
我们正常理解的线程安全问题是指单进程多线程模型内部多个线程操作进程内共享内存导致的数据资源充突。而 Redis 的线程安全问题的产生,并不是来自于 Redis 服务器内部。
问题的产生并不是来自于 Redis 服务器内部。
这里的并发问题指的是,多个客户端同时对一个key进行写操作(如库存增减)。多个客户端就相当于同一进程下的多个线程,如果多个客户端之间没有良好的数据同步策略,就会产生类似线程安全的问题。
解决方案
- 加时间戳:操作a变量时候,额外维护一个时间戳
- 基于消息队列:把所有操作写入同一个队列,利用消息队列把所有操作串行化
- 利用原子性:使用本身就具有原子性的redis 函数:incryby
- 利用原子性:使用 Lua 脚本:将多个操作形成一个原子操作
- Redis事务:通过watch+mutil解决并发修改的问题
如何解决redis并发竞争key
Redis 是并发安全的吗?你确定?
答案最全 - Redis 核心技术与实战 - 29 | 无锁的原子操作:Redis如何应对并发访问?
实际场景方案 - 电商库存系统的防超卖和高并发扣减方案
实际举例 - 事务应用 - Redis:解决分布式高并发修改同一个Key的问题
Redis(十一):Redis的事务功能详解
redis zset 底层的数据结构是什么
跳跃表
跳跃表和堆排序的区别是什么
算法实现
- LRU
- LFU
- SkipList
高并发下redis和数据库的强一致如何保证(redis与mysql数据一致性)
主要考虑两个问题:
1、执行顺序的问题:先更新缓存还是先更新数据库?
2、更新缓存的策略问题:当缓存中的内容变化时,是选择修改缓存(update),还是直接淘汰缓存(delete)?
总体:删除缓存好过更新缓存;
针对这两点问题,一共可以分为四种方案:
1、先更新缓存,再更新数据库;// 数据丢失风险(挂机) - 直接不考虑
2、先更新数据库,再更新缓存;// 1. 数据上:脏数据(A库B库B缓A缓导致);2. 业务上:写入场景多,缓存频繁更新;写入db后,需要再计算后写入缓存,浪费性能
3、先删除缓存,再更新数据库;
4、先更新数据库,再删除缓存。
一条口诀验证以上四种方式是否会有问题:两个线程并发,写一半,查进来;查一半,写进来
先删除缓存,再更新数据库 - 请求A更新,请求B查询,B的操作夹在了A删缓和写库之间,造成缓存脏数据
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库
上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
那么,如何解决呢?采用延时双删策略,即(1)先淘汰缓存(2)再写数据库(这两步和原来一样)(3)休眠1秒,再次淘汰缓存(最好异步)。进一步提出问题:第(3)步失败咋办呢?答:写入MQ,(异步)自消费重试先更新数据库,再删缓存
不是的。假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
(1)缓存刚好失效
(2)请求A查询数据库,得一个旧值
(3)请求B将新值写入数据库
(4)请求B删除缓存
(5)请求A将查到的旧值写入缓存
ok,如果发生上述情况,确实是会发生脏数据。
然而,发生这种情况的概率又有多少呢?
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。假设,有人非要抬杠,有强迫症,一定要解决怎么办?采用延时双删策略
还有一个问题:删缓存失败了?答:写入MQ,自消费
所以,归纳下,相对而言,采用先更新数据库,再删缓存。无论是先更新库再删缓存,还是先删缓存,再更新库,并发的问题总体可采用延时双删,如果删除失败,放MQ,(异步)自消费重试
独孤烟 - 分布式之数据库和缓存双写一致性方案解析
独孤烟 - 分布式之数据库和缓存双写一致性方案解析二
独孤烟 - 分布式之数据库和缓存双写一致性方案解析三
mysql
Innodb
索引数据结构 B+tree
Mysql 索引的底层实现原理
Buffer Pool
Buffer Pool 有三个链表 free链表,flush链表,LRU链表
Buffer Pool中的LRU淘汰算法
https://www.jianshu.com/p/7cb6d7d59064
change buffer详解
The change buffer is a special data structure that caches changes to secondary index pages when those pages are not in the buffer pool. The buffered changes, which may result from INSERT, UPDATE, or DELETE operations (DML), are merged later when the pages are loaded into the buffer pool by other read operations.
Change buffer的主要目的是将对二级索引的数据操作缓存下来,以此减少二级索引的随机IO,并达到操作合并的效果。
InnoDB change buffer可以对三种类型的操作进行缓存:INSERT、DELETE-MARK 、DELETE操作,前两种对应用户线程操作,第三种则由purge操作触发。
mysql 写多读少场景,更新一条语句时,条件中唯一索引和普通索引哪个选择更好的,为什么
本质想问的是 mysql change buffer
入门:https://www.cnblogs.com/myseries/p/11307204.html
入门:https://www.modb.pro/db/112469
深入:https://www.modb.pro/db/50671
Change buffer 与 Buffer Pool 的区别
事务
幻读的解决
sql语句加锁分析
1.普通select(也叫一致性读)语句加锁分析
2.特殊select(也叫锁定读(in shard mode and for update))语句加锁分析
3.update and delete语句时加锁分析
Rationale behind difference between unique and non-unique indexes in MySQL InnoDB next-key locking
mysql事务是如何实现的,回滚时是怎么个操作流程,
事务实现的原理,我认为便是事务如何保证ACID,即原子性,一致性,隔离性,持久性。
也即是想问redo,undo的知识点
mysql为什么使用B+树,而mongdb使用B树呢
mysql主从的实现方式,哪些方式
https://www.cnblogs.com/rickiyang/p/13856388.html
mysql是怎样运行的小结
redo log & binlog & undo log写入数据的顺序和具体流程 自问
bufferPool redo日志 undo日志 分别何时产生,何时刷盘,何时删除
因为只有改动才会涉及redo,undo。所以假设执行的 update 语句
redo log + undo log的简化版本过程
redo log是用来恢复数据的,用于保障已提交事务的持久性;
undo log是用来回滚事务的,用于保障未提交事务的原子性。
1 | 1. 查询的数据若在Buffer Pool存在,则直接使用,不存在则读取磁盘中的数据并放入Buffer Pool,再使用; |
举例:update set A=3 where A=1
- 事务开始
- 记录A=1到undo log
- 修改A=3
- 记录A=3到 redo log
- 事务提交
链接:
https://www.jianshu.com/p/43fb7bc40648
https://www.jianshu.com/p/dbbd8d601f8c
两个重要的指针 roll-pointor & next-record
roll_pointor:记录指向它的 undo 日志的指针
next_record :记录指向下一条记录的指针
mysql主从复制延迟解决方案
主从复制原理
当在从库上启动复制时,首先创建I/O线程连接主库,主库随后创建Binlog Dump线程读取数据库事件并发送给I/O线程,I/O线程获取到事件数据后更新到从库的中继日志Relay Log中去,之后从库上的SQL线程读取中继日志Relay Log中更新的数据库事件并应用,
细化一下有如下几个步骤:
1 | 1、MySQL主库在事务提交时把数据变更(insert、delet、update)作为事件日志记录在二进制日志表(binlog)里面。 |
延迟原因
MySQL主从复制,读写分离是我们常用的数据库架构,但是在并发量较大、数据变化大的场景下,主从延时会比较严重。
延迟的本质原因是:系统TPS并发较高时,主库产生的DML(也包含一部分DDL)数量超过Slave一个Sql线程所能承受的范围,效率就降低了。
我们看到这个sql thread 是单个线程,所以他在重做RelayLog的时候,能力也是有限的。主库是并发的事务提交,但是从库只能串行执行,速度比主库慢
解决方案
分治 - 分库分表
数据库分区是永恒的话题,主从延迟一定程度上是单台数据库主服务操作过于频繁,使得单线程的SQL thread 疲于应付。可以适当的从功能上对数据库进行拆分,分担压力。
从库同步完成后响应
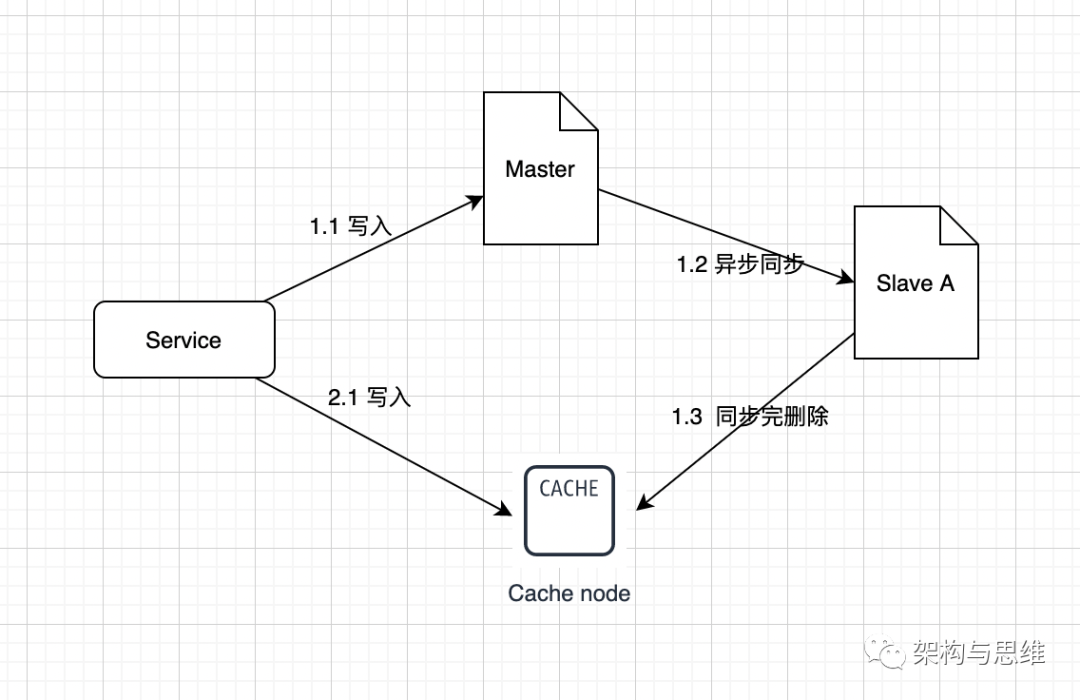
适当引入缓存
可以引入redis或者其他nosql数据库来存储我们经常会产生主从延迟的业务数据。当我在写入数据库的同时,我们再写入一份到redis中。
读取数据的时候,我们可以先去查看redis中是否有这个数据,如果有我们就可以直接从redis中读取这个数据。当数据真正同步到数据库中的时候,再从redis中把数据删除。如下图:
多线程重放RelayLog
MySQL使用单线程重放RelayLog,那能不能在这上面做解法呢,比如使用多线程并行重放RelayLog,就可以缩短时间。但是这个对数据一致性是个考验。
需要考虑如何分割RelayLog,才能够让多个数据库实例,多个线程并行重放RelayLog,不会出现不一致。比如RelayLog包含这三条语句给学生授予学分的记录,你就不知道结果会变成什么。可能是806甚至是721。
相同库表上的写操作,用相同的线程来重放RelayLog;不同库表上的写操作,可以并发用多个线程并发来重放RelayLog。
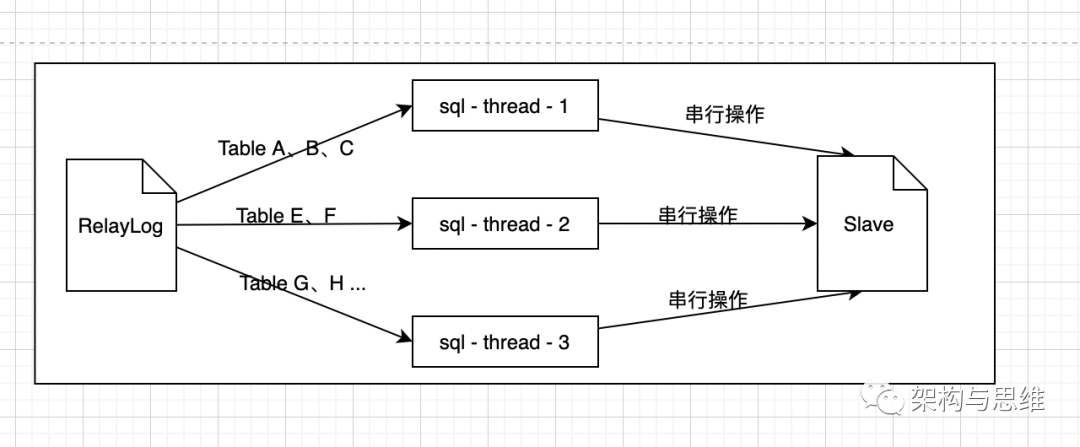
设计一个哈希算法,hash(db-name) % thread-num,表名称hash之后再模上线程数,就能很轻易做到,同一个库表上的写操作,被同一个重放线程串行执行,做到提效的目的。
少量读业务直连主库
kafka
kafka中的消费是基于拉模式的
可靠性的保证(kafka如何保证消息的可靠的)
- 生产者保证:1.acks确认机制: request.required.acks;2.isr副本集合;3.重试
- broker保证:1.副本机制(数据多份);2.同步机制。leader挂掉,从followers选举一个成为新的leader;3.offset位移提交时机
kafka中的消息有三种传递语义:
- at most once:最多一次。消息可能丢失也可能被处理,但最多只会被处理一次。
- at least once:至少一次。消息不会丢失,但可能被处理多次。可能重复,不会丢失。
- exactly once:精确传递一次。消息被处理且只会被处理一次。不丢失不重复就一次。
进阶,Kafka 如何保证消息不丢失?
刨根问底,kafka 到底会不会丢消息
When you can lose messages in Kafka
生产者的可靠性保证
通过acks和min.insync.replicas和unclean.leader.election.enable的配合,保证在Kafka配置为CP系统时,要么不工作,要么得到ack后,消息不会丢失且消息状态一致。
acks策略
回答生产者的可靠性保证,即回答:
发消息之后有没有ack?
发消息收到ack后,是不是消息就不会丢失了?
而Kafka通过配置来指定producer生产者在发送消息时的ack策略:
Request.required.acks = -1 (全量同步确认,强可靠性保证);
Request.required.acks = 1 (leader 确认收到, 默认);
Request.required.acks = 0 (不确认,但是吞吐量大)。
ISR
isr = in-sync replica set
所有 Follower 完成同步,Producer 才能继续发送数据,设想有一个 Follower 因为某种原因出现故障,那 Leader 就要一直等到它完成同步。
这个问题怎么解决?Leader维护了一个动态的 in-sync replica set(ISR):和 Leader 保持同步的 Follower 集合。
当 ISR 集合中的 Follower 完成数据的同步之后, Follower 就会给 Leader 发送 ACK。
如果 Follower 长时间未向 Leader 同步数据,则该 Follower 将被踢出 ISR 集合,该时间阈值由 replica.lag.time.max.ms 参数设定。Leader 发生故障后,就会从 ISR 中选举出新的 Leader。
min.insync.replicas
参数用于保证当前集群中处于正常同步状态的副本follower数量,当实际值小于配置值时,集群停止服务。如果配置为 N/2+1, 即多一半的数量,则在满足此条件下,通过算法保证强一致性。当不满足配置数时,牺牲可用性即停服。
unclean.leader.election.enable
异常情况下,leader挂掉,此时需要重新从follower选举leader。可以为f2或者f3。

如果选举f3为新leader, 则可能会发生消息截断,因为f3还未同步msg4的数据。Kafka通过unclean.leader.election.enable来控制在这种情况下,是否可以选举f3为leader。旧版本中默认为true,在某个版本下已默认为false,避免这种情况下消息截断地出现。
重试
网络抖动,可以重试
消息体过大,broker 拒收
CP or AP
- 如果想实现Kafka配置为 CP系统,配置需要如下:
request.required.acks=-1
min.insync.replicas = ${N/2 + 1}
unclean.leader.election.enable = false
- 如果想实现Kafka配置为 AP系统,配置需要如下:
request.required.acks=1
min.insync.replicas = 1
unclean.leader.election.enable = false
思考:分区与副本因子有关系吗,什么关系
新的消费(组)进来时,为什么找不到消费位移,不是broker存着呢吗
broker的可靠性保证
- 副本机制(备份)和同步机制
副本机制:Kafka通过分区的多副本策略来解决消息的备份问题;同步机制:同时通过HW和LEO的标识,通过ISR和OSR的概念,一起解决数据同步一致性的问题。
副本机制
Kafka通过分区多副本即前文提到的Partition 的replica(副本) 分布在跟 partition 不相同的机器上,达到数据冗余。
同步机制
消息通过producer发送到broker之后,还会遇到很多问题:
Partition leader 写入成功,follower什么时候同步?
Leader写入成功,消费者什么时候能读到这条消息?
Leader写入成功后,leader重启,重启后消息状态还正常吗?
Leader重启,如何选举新的leader?
这些问题集中在:消息落到broker后,集群通过何种机制来保证不同副本间的消息状态一致性。
不同副本的状态同步形成了同步机制。同步机制涉及了AR、ISR、OSR、HW和LEO等概念。
而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。LEO: Log End Offset
https://zhuanlan.zhihu.com/p/302704003
offset详解
对于分区来说是偏移量,对于消费者是位移
位移提交时机是难点
生产者发送消息到broker的过程
消费者从broker消费消息的过程
kafka offset存在哪里,为啥用kafka不是其他消息组件,他最大能支持多少并发,如何保证消息的可靠的
offset 存在 Broker 中
kafka 是如何保证消息可靠的
在以下三步中每一步都可能会出现丢失数据的情况,那么 Kafka 到底在什么情况下才能保证消息不丢失呢?
1)Producer 端发送消息给 Kafka Broker 端。
丢消息场景:
Producer 端为了提升发送效率,减少IO操作,发送数据的时候是将多个请求合并成一个个 RecordBatch,并将其封装转换成 Request 请求「异步」将数据发送出去(也可以按时间间隔方式,达到时间间隔自动发送),所以 Producer 端消息丢失更多是因为消息根本就没有发送到 Kafka Broker 端。
导致 Producer 端消息没有发送成功有以下原因:
- 网络原因:由于网络抖动导致数据根本就没发送到 Broker 端。
- 数据原因:消息体太大超出 Broker 承受范围而导致 Broker 拒收消息。
producer 即使配置 ack 也可能丢消息:broker 挂了,producer 没有收到 ack
acks =0:由于发送后就自认为发送成功,这时如果发生网络抖动, Producer 端并不会校验 ACK 自然也就丢了,且无法重试。
acks = 1:消息发送 Leader Parition 接收成功就表示发送成功,这时只要 Leader Partition 不 Crash 掉,就可以保证 Leader Partition 不丢数据,但是如果 Leader Partition 异常 Crash 掉了,Follower Partition 还未同步完数据且没有 ACK,这时就会丢数据。
acks = -1 或者 all:消息发送需要等待 ISR 中 Leader Partition 和 所有的 Follower Partition 都确认收到消息才算发送成功,可靠性最高,但也不能保证不丢数据,比如当 ISR 中只剩下 Leader Partition 了,这样就变成 acks = 1 的情况了。
解决方案
(1)网络抖动导致消息丢失,Producer 端可以进行重试。producer 端配置重试次数 retries 和 重试时间 retry.backoff.ms
这样 Producer 端就会一直进行重试直到 Broker 端返回 ACK 标识,同时只有一个连接向 Broker 发送数据保证了消息的顺序性。
(2)消息大小不合格,可以进行适当调整,符合 Broker 承受范围再发送。
2)Kafka Broker 将消息进行同步并持久化数据。
在剖析Broker 端丢失场景的时候, 我们得出其是通过「异步批量刷盘」的策略,先将数据存储到「PageCache」,再进行异步刷盘, 由于没有提供 「同步刷盘」策略,因此 Kafka 是通过「多分区多副本」的方式来最大限度的保证数据不丢失。
我们可以通过以下参数配合来保证:
4.2.1 unclean.leader.election.enable:
该参数表示有哪些 Follower 可以有资格被选举为 Leader , 如果一个 Follower 的数据落后 Leader 太多,那么一旦它被选举为新的 Leader, 数据就会丢失,因此我们要将其设置为false,防止此类情况发生。
4.2.2 replication.factor:
该参数表示分区副本的个数。建议设置replication.factor >=3, 这样如果 Leader 副本异常 Crash 掉,Follower 副本会被选举为新的 Leader 副本继续提供服务。
4.2.3 min.insync.replicas:
该参数表示消息至少要被写入成功到 ISR 多少个副本才算”已提交”,建议设置min.insync.replicas > 1,这样才可以提升消息持久性,保证数据不丢失。
另外我们还需要确保一下replication.factor > min.insync.replicas, 如果相等,只要有一个副本异常 Crash 掉,整个分区就无法正常工作了,因此推荐设置成:replication.factor =min.insync.replicas +1, 最大限度保证系统可用性。
3)Consumer 端从Kafka Broker 将消息拉取并进行消费。
在剖析 Consumer 端丢失场景的时候,我们得出其拉取完消息后是需要提交 Offset 位移信息的,因此为了不丢数据,正确的做法是:拉取数据、业务逻辑处理、提交消费 Offset 位移信息。
我们还需要设置参数enable.auto.commit = false, 采用手动提交位移的方式。
另外对于消费消息重复的情况,业务自己保证幂等性, 保证只成功消费一次即可。
消费者如何保证一定成功消费消息 - 重试实现
这里已kafka 为例
kafka 消费重试实现
实际场景:消费者服务中,接收了一个消息,但消费者服务自身业务逻辑处理异常了,相当于消息消费失败了。消费者需要重新消费这条消息,重新走业务逻辑。如何解决这个场景呢
代码里重试
1 | int i = 0 |
缺点:重试间隔时间没有,代码侵入性高
offset重置
在消息消费失败时,SeekToCurrentErrorHandler 会将 调用 Kafka Consumer 的 seek(TopicPartition partition, long offset) 方法,将 Consumer 对于该消息对应的 TopicPartition 分区的本地进度设置成该消息的位置。
缺点:影响重置位置后面的已经成功消费的消息了
基于数据库任务表的扫描
在数据库中增加一个任务的状态表,然后用一个定时任务去扫描任务表中,失败的任务,然后进行重试,其中记录下重试的次数即可
优点:实现简单,一般这种离线任务,根据统计的需求,都会有一个任务状态表的,所以仅仅是增加一个定时任务去扫表
缺点:性能较差,定时任务,一般都在无意义的扫描,浪费性能
新增重试队列 - 创建一个重试topic
失败的消息写入主题’main_topic’中,如果此消息的处理失败,那么我们应该在5分钟内再次尝试。我们怎么做?我们应该向’retry_topic’写一条新消息,它包装失败的消息并添加2个字段:
- ‘retry_number’,值为1
- ‘retry_timestamp’,其值计算为现在+ 5分钟
这意味着’main_topic’使用者将失败的消息处理的责任委托给另一个组件。’main_topic’消费者未被阻止,可以接收下一条消息。’retry_topic’消费者将立即收到’main_topic’消费者发布的消息。它必须从消息中读取’retry_timestamp’值并等到那一刻,阻塞线程。线程唤醒后,它将再次尝试处理该消息。如果成功,那么我们可以获取下一个可用消息。否则我们必须再次尝试。我们要做的是克隆消息,递增’attempt_number’值(它将为2)并将’retry_timestamp’值设置为now + 5分钟。消息克隆将再次发布到’retry__topic。
如果我们到达重试最高次数。现在是时候说“停止”了。我们将消息写入’failed_topic’并将此消息视为未处理。有人必须手动处理它。
kafka rebalance
原因
- 消费者心跳超时,导致 rebalance。
- 消费者处理时间过长,导致 rebalance。
rebalance时间长原因
- Consumers needs to finish processing the data they polled last time.
- Coordinator waits for Consumer to send JoinGroup request - for how long?
- Consumers send SyncGroup request (is there a delay between receiving JoinGroup response and sending SyncGroup request?)
有关参数
要学会处理 rebalance 问题,我们需要先搞清楚 kafaka 消费者配置的四个参数:
- session.timeout.ms 设置了超时时间
- heartbeat.interval.ms 心跳时间间隔
- max.poll.interval.ms 每次消费的处理时间
- max.poll.records 每次消费的消息数
session.timeout.ms 表示 consumer 向 broker 发送心跳的超时时间。例如 session.timeout.ms = 180000 表示在最长 180 秒内 broker 没收到 consumer 的心跳,那么 broker 就认为该 consumer 死亡了,会启动 rebalance。
heartbeat.interval.ms 表示 consumer 每次向 broker 发送心跳的时间间隔。heartbeat.interval.ms = 60000 表示 consumer 每 60 秒向 broker 发送一次心跳。一般来说,session.timeout.ms 的值是 heartbeat.interval.ms 值的 3 倍以上。
max.poll.interval.ms 表示 consumer 每两次 poll 消息的时间间隔。简单地说,其实就是 consumer 每次消费消息的时长。如果消息处理的逻辑很重,那么市场就要相应延长。否则如果时间到了 consumer 还么消费完,broker 会默认认为 consumer 死了,发起 rebalance。
max.poll.records 表示每次消费的时候,获取多少条消息。获取的消息条数越多,需要处理的时间越长。所以每次拉取的消息数不能太多,需要保证在 max.poll.interval.ms 设置的时间内能消费完,否则会发生 rebalance。
简单来说,会导致崩溃的几个点是:
消费者心跳超时,导致 rebalance。
消费者处理时间过长,导致 rebalance。
方案
- 增大
session.timeout.ms值,增大max.poll.interval.ms值,减小max.poll.records值 - take advantage of Kafka’s
static group membership, which was made available as of Apache Kafka 2.3 This is the group.instance.id setting for consumers, set uniquely on each consumer within a group - enable
incremental cooperative rebalance protocolinstead of the default “stop the world” protocol. With incremental cooperative rebalancing (set on the consumers’ configuration as partition.assignment.strategy: ”cooperative-sticky”), available for consumers as of Apache Kafka 2.4,
understanding-kafkas-consumer-group-rebalancing
solving-my-weird-kafka-rebalancing-problems
kafka 有序性
producer发送消息的有序性
broker维护一个单调递增的Sequence Number
详情:Kafka如何保证消息的顺序性
- 使用一个分区 - 实现简单,但有热点瓶颈问题
- 多个分区,某类数据(如同一个订单)发送到同一分区
consumer多线程消费消息,如何保证消息消费有序性
消费者端创建多个内存队列,同类数据(同一个订单id)都路由到同一个内存队列;然后每个线程分别消费一个内存队列即可,这样就能保证顺序性。
详情:Kafka如何保证消息的顺序性
如果要全局有序性,则消息放入队列,多线程从一个队列拿消息,拿到消息,处理成功后从队列中删除
spring
spring boot
一文告诉你Spring是如何利用”三级缓存”巧妙解决Bean的循环依赖问题的
spring cloud
Eureka节点信息同步延迟及单个注册中心节点load偏高问题的排查
接口幂等性
什么是接口的幂等性,如何实现接口幂等性?一文搞定
高并发下如何保证接口的幂等性?
计算机网络
经典大神斯坦福大学 Introduction to Computer Networking CS 144
CS 144: Introduction to Computer Networking
https://github.com/huangrt01/CS-Notes
https://github.com/huangrt01/CS-Notes/blob/master/Notes/Output/Computer-Networking-A-Top-Down-Approach.md
Wireshark实验文档的翻译和解答。
CS144
计算机网络】Stanford CS144 Lab
CS144 Lab 翻译
io
同步异步
IO模型
目前unix存在五种IO模型(这也和上一篇文章:Unix IO 模型 中提到的一致),分别是:
- 阻塞型 IO(blocking I/O)
- 非阻塞性IO(nonblocking I/O)
- IO多路复用(I/O multiplexing)
- 信号驱动IO(signal driven I/O)
- 异步IO(asynchronous I/O)
IO的两个阶段
- 等待数据准备好
- 将数据从内核缓冲区复制到用户进程缓冲区
同步,异步的区别
那么究竟什么是同步和异步的区别呢?请重点读一下原文6.2节中的信号驱动IO和异步IO中的比较。最后总结出来是:
- 同步IO,需要用户进程主动将存放在内核缓冲区中的数据拷贝到用户进程中。
- 异步IO,内核会自动将数据从内核缓冲区拷贝到用户缓冲区,然后再通知用户。
这样,同步和异步的概念就非常明显了。以上的五种IO模型,前面四种都是同步的,只有第五种IO模型才是异步的IO。
阻塞和非阻塞

结论
- 判断IO是同步还是异步,是看谁主动将数据拷贝到用户进程。
- select或者poll,epoll,是同步调用,进行此调用的用户进程也处于阻塞状态。
tcp/ip 网络
https://www.bilibili.com/video/BV1Yk4y1y76r?p=58&share_source=copy_web
https://www.bilibili.com/video/BV1Ji4y1M7Y1?p=1
数据结构
二叉树
- 二叉树:一个节点有两个子树,一个左子树,一个右子树。
- 二叉查找树:每个节点都大于他的左子树,同时小于他的右子。查找实现
- 二叉堆:每个节点都大于他的左右子树
算法
第一遍,看题目,想解法,如果十几分分想不出来直接看题解,看看别人的解法,最好能够默写出来
第二遍,自己尝试写出
第三遍,隔几天后再次写一下,体会+上自己的优化
第四遍,一周过去后,再来一一遍
第五遍,复习,例如面试前。 (不一定是五遍,而是要做出来自己的体会和思考才是最重要的。) 如果有小手指,帮忙点点。上面的方法是收到,覃超老师的指导的方法。
下面推一波,自己使用觉得非常好的刻意练习的工具: 推荐notion辅助我们刻意练习,使用了一个月多,感觉这app真心不错,学习和工作都能用起来。 通过下面的链接,注册一个账号玩一下吧:
https://www.notion.so/?r=8fa23ab14e76405daa2e6efb38569c1b
入门视频: https://www.bilibili.com/video/BV1gQ4y1K76r
入门搭建的自己的home page: https://www.bilibili.com/video/BV1Zb411H7xC
附上非常好用的刻意练习模板,也是目前自己在使用的模板: https://www.notion.so/Spaced-Repetition-Battleground-c1f738213e8b4bee871999474bb17bf0
从来没有那么喜欢一个工具,因为这个工具真的满足自己目前的学习和工作的需求。 如果你也喜欢一个工具帮助自己管理时间,管理自己的学习,管理自己的博客等等,这里all in one,而且还做的好。缺点就是可能需要梯子,有时候反应不断太快。 https://www.notion.so/?r=8fa23ab14e76405daa2e6efb38569c1b
刻意练习不是简单重复,而是跳出自己的舒适圈,不断扩大自己的舒适圈,同时在练习的过程也是需要不断反馈和改进。
架构
架构理论
软件开发中的原则 - SOLID
分布式理论 - CAP
分布式理论 - BASE
事务理论 - ACID
微服务基础 - 康威定律
- 第一定律:人是复杂得社会动物
- 第二定律:一口气吃不成胖子,先搞定能搞定的
- 第三定律:种瓜得瓜,做独立自治的子系统减少沟通成本
性能
性能优化
从用户浏览器到数据库,影响用户请求的所有环节都可以进行性能优化
- 面试被问到的时候,可以边画图边阐述,一个请求从浏览器到数据库整个链路的方式。
- 浏览器:浏览器缓存(304:not Modified 200:cache-control max-age:36000),页面压缩,减少Cookie传输
- CDN:将网站静态资源分发至离用户最近的网络服务商机房
- 应用服务器:本地缓存,分布式缓存,异步,高并发下使用集群
- 代码:使用多线程,改善内存管理
- 数据库:索引,缓存,sql优化
性能优化指标
响应时间,TPS,系统性能计数器等
性能优化 三个“要”原则是:
- 要优先查最大的性能瓶颈
- 性能分析要确诊性能问题的根因
- 性能优化要考虑各种的情况。
- 足够多的测量
- 权衡利弊
性能优化 三个“不要”的原则是:
- 不要做过度的、反常态的优化
- 不要过早做不成熟的优化
- 不要做表面的肤浅优化。
可扩展性
可扩展性关注的是功能需求。使其快速响应需求变化
1. 预测变化
- 唯一不变的是变化
- 2年法则
对于架构师来说,如何把握预测的程度和提升预测结果的准确性
2. 应对变化
方案一:提炼出“变化层”和“不变化层”
方案二:提炼出“抽象层”和“实现层”
可扩展性 vs 可伸缩性区别
可伸缩性:面对用户量的增加,采取的一些措施。可伸缩性更偏向系统和服务,如水平伸缩,垂直伸缩。可伸缩性是指系统通过增加或减少硬件水平从而提升或降低系统性能的难易程度。可伸缩性分为scale up和scale out。scale up是指提高单台服务器的硬件水平来提高系统的整体处理能力,可以调整的有CPU,存储,内存等;scale out是指通过增加系统的处理节点的方式来提高系统的整体处理能力。
可扩展性:面对需求量的增加,采取的一些措施。可扩展性更偏向需求,对需求变化的预测,预测变化,应用变化。可扩展性是软件系统应对需求增加或需求变化的能力。
可用性
维基百科:系统的运作时间,工作时间比总时间,一般用百分比表示,例如99.999%(5个9)。
关注的是服务总体的持续时间,系统在给定时间内总体的运行时间越长,可用性越高。
可用性 = 正常运行时间/(正常运行时间 + 停机时间)
可用性度量
业界通常用几个9来衡量网站的可用性。
高可用
- 架构的高可用:数据和服务的冗余备份及失效转移
- 应用的高可用:应用无状态时使用负载均衡
- 服务的高可用:
- 分级管理(核心应用和服务优先使用更好地硬件)
- 超时设置
- 异步调用:避免一个服务失败导致整个应用请求失败
- 服务降级
- 幂等性设计
数据的高可用:数据备份和失效转移,数据备份保证数据有多个副本
数据高可用有几个层面的意思:数据持久性,数据可访问性,数据一致性软件质量保证的高可用
- 自动化测试
- 预发布验证
- 代码控制:分支开发,主干发布
- 自动化发布
- 灰度发布
- 监控
- 数据采集
a. 用户日志收集,服务日志收集
b. 性能监控
c. 运行数据报告
- 数据采集
- 监控管理
a. 报警
b. 失效转移
c. 自动降级
- 监控管理
可靠性
维基百科:可靠性(Reliability)是指定时间 t 内,产生正式输出的机率。
可靠性(Reliability)是指系统可以无故障地持续运行。与可用性相反,可靠性是根据时间间隔而不是任何时刻来进行定义的。
可靠性相关的几个指标如下:平均无故障时间,平均修复时间,平均失效时间
MTBF(平均修复时间) = 运行时间(小时)/故障次数
我们举个一个例子来说明二者的区别。如果系统在每小时崩溃1ms,那么它的可用性就超过99.9999%,但是它还是高度不可靠,因为它只能无故障运行1小时。与之类似,如果一个系统从来不崩溃,但是每年要停机两星期,那么它是高度可靠的,但是可用性只有96%。
可用性 vs 可靠性区别
见各自定义
链接:https://www.jianshu.com/p/32925821dbfb
你们那微服务是怎么划(拆)分的
为什么拆分
业务系统往微服务化拆分也非常有必要,原因是:
- 随着业务的发展,应用程序本身的复杂度会不断增加,同样会产生熵增现象。
- 业务系统的功能越来越多,参与开发迭代的人员也越多,多个人维护一个非常庞大的项目,很容易出现问题。
- 单个应用系统很难实现横向扩容,并且由于服务器资源有限,导致所有的请求都集中请求到某个服务器节点,造成资源消耗过大,使得系统不稳定
- 测试、部署成本越来越高
最终要的是,单个应用在性能上的瓶颈很难突破,也就是说如果我们要支持18000QPS,单个服务节点肯定无法支撑,所以服务拆分的好处,就是可以利用多个计算机阶段组成一个大规模的分布式计算网络,通过网络通信的方式完成一整套业务逻辑。
如何拆分 - 拆分策略
- 基于业务逻辑拆分
1.1 领域模型拆分 - 边界性问题
数据领域:如商品域和订单域
部门组织领域
1.2 用户群体拆分
- 基于可扩展拆分
系统中变与不变的部分,不变的部分一般是成熟的、通用的服务功能,变的部分一般是改动比较多、满足业务迭代扩展性需要的功能,我们可以将不变的部分拆分出来,作为共用的服务,将变的部分独立出来满足个性化扩展需要。
根据二八原则, 系统中经常变动的部分大约只占 20%,而剩下的 80% 基本不变或极少变化,这样的拆分也解决了发布频率过多而影响成熟服务稳定性的问题。
- 基于可靠性拆分
3.1 核心模块拆分
把一些重要的模块独立放在一个集群上,不与其他模块混用,而这个独立的集群,服务机性能要是最好的。
3.2 主次链路拆分
在各个业务系统中,其实都会有主次业务链路。主业务链条,完成了业务系统中最核心的那部分工作。而次链路是保证其他基础功能的稳定运行。
- 基于性能需求拆分
访问量特别大,访问频率特别高的业务,又要保证高效的响应能力,这些业务对性能的要求特别高。比如积分竞拍、低价秒杀、**抢购。
我们要识别出某些超高并发量的业务,尽可能把这部分业务独立拆分出来。这么做的原因非常简单,一个保证满足高性能业务需求,另一个保证业务的独立性,不互相影响。
类似积分竞拍、超低价秒杀、**抢购,对瞬间峰值和计算性能要求是非常高的。这部分的业务如果跟其他通用业务放在一块,一个是可能互相影响,比如某个链路阻塞,会导致雪崩沿调用链向上传递。
https://heapdump.cn/article/3209555
- 服务拆分还需要根据当前技术团队和公司所处的状态来进行。
不需要过分的追求微服务,否则会导致业务逻辑过于分散,技术架构太过负载,再加上团队的基础设施还不够完善,导致整个交付的时间拉长,对公司的发展来说会造成较大的影响。
- 水平拆分与垂直拆分
微服务间数据一致性
理论依据
BASE理论:核心思想是即使无法做到强一致性,应用应该可以采用合适的方式达到最终一致性
- ❶ 基本可用(Basically Available):指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
- ❷ 软状态(Soft State):允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。
- ❸ 最终一致性(Eventual Consistency):最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
事件通知模式
主服务完成后将结果通过事件(常常是消息队列)传递给从服务,从服务在接受到消息后进行消费,完成业务,从而达到主服务与从服务间的消息一致性
事件通知模式详细参看:微服务下数据一致性 - 事件通知模式-部分
同步事件通知
业务处理与消息发送同步执行,实现逻辑如下1
2
3
4
5
6
7bool result = dao.update(data); // 1. 操作数据库
// 操作数据库失败,会抛出异常
if(result){ // 2. 如果数据库操作成功则发送消息
mq.send(data);
}
// 如果方法执行失败,会抛出异常
同步事件通知问题
主服务自身DB 处理后,发送消息(kafka)到broker,这时候broker要给主服务发ack,但是此时broker已经收到消息了,但回ack 时,网络出问题了。造成broker 已经成功收到消息,但主服务认为broker没有收到,那么主服务就会回滚DB 操作。最后的结果是主服务回滚了,broker 的消息被消费者消费了。
异步事件
为了解决上述同步事件中描述的同步事件的问题,异步事件通知模式被发展了出来,既业务服务和事件服务解耦,事件异步进行,由单独的事件服务保证事件的可靠投递。
本地事件服务
当业务执行时,在同一个本地事务中将事件写入本地事件表,同时投递该事件,如果事件投递成功,则将该事件从事件表中删除。如果投递失败,则使用事件服务定时地异步统一处理投递失败的事件,进行重新投递,直到事件被正确投递,并将事件从事件表中删除。这种方式最大可能地保证了事件投递的实效性,并且当第一次投递失败后,也能使用异步事件服务保证事件至少被投递一次。
然而,这种使用本地事件服务保证可靠事件通知的方式也有它的不足之处,那便是业务仍旧与事件服务有一定耦合(第一次同步投递时),更为严重的是,本地事务需要负责额外的事件表的操作,为数据库带来了压力
外部事件服务
外部事件服务在本地事件服务的基础上更进了一步,将事件服务独立出主业务服务,主业务服务不在对事件服务有任何强依赖。
业务服务在提交前,向事件服务发送事件,事件服务只记录事件,并不发送。业务服务在提交或回滚后通知事件服务,事件服务发送事件或者删除事件。
但是外部事件服务也有问题:业务系统无法确认是否成功发送事件给事件服务,所以事件服务需要定时向业务系统查询,根据业务系统的返回来决定发送或者删除该事件。也就是对账,对账是最后的防线
以上解决的问题,称为解决微服务数据一致性问题。从另一个角度,生产者消费者的角度,也可以称为是解决了生产者产生的数据如何自身处理成功的同时,将数据一定要发送到消费者那里。那么消费者是如何保证消息一定要消费成功的呢
消费者如何保证一定成功消费消息 - 重试实现
这里已kafka 为例
kafka 消费重试实现
实际场景:消费者服务中,接收了一个消息,但消费者服务自身业务逻辑处理异常了,相当于消息消费失败了。消费者需要重新消费这条消息,重新走业务逻辑。如何解决这个场景呢代码里重试
1
2
3
4
5
6
7
8
9int i = 0
try{
// 处理业务逻辑
} catch() {
while(i<3) {
i++;
// 重新处理业务逻辑
}
}
缺点:重试间隔时间没有,代码侵入性高
- offset重置
在消息消费失败时,SeekToCurrentErrorHandler 会将 调用 Kafka Consumer 的 seek(TopicPartition partition, long offset) 方法,将 Consumer 对于该消息对应的 TopicPartition 分区的本地进度设置成该消息的位置。
缺点:影响重置位置后面的已经成功消费的消息了
- 基于数据库任务表的扫描
在数据库中增加一个任务的状态表,然后用一个定时任务去扫描任务表中,失败的任务,然后进行重试,其中记录下重试的次数即可
优点:实现简单,一般这种离线任务,根据统计的需求,都会有一个任务状态表的,所以仅仅是增加一个定时任务去扫表
缺点:性能较差,定时任务,一般都在无意义的扫描,浪费性能
- 新增重试队列 - 创建一个重试topic
失败的消息写入主题’main_topic’中,如果此消息的处理失败,那么我们应该在5分钟内再次尝试。我们怎么做?我们应该向’retry_topic’写一条新消息,它包装失败的消息并添加2个字段:
- ‘retry_number’,值为1
- ‘retry_timestamp’,其值计算为现在+ 5分钟
这意味着’main_topic’使用者将失败的消息处理的责任委托给另一个组件。’main_topic’消费者未被阻止,可以接收下一条消息。’retry_topic’消费者将立即收到’main_topic’消费者发布的消息。它必须从消息中读取’retry_timestamp’值并等到那一刻,阻塞线程。线程唤醒后,它将再次尝试处理该消息。如果成功,那么我们可以获取下一个可用消息。否则我们必须再次尝试。我们要做的是克隆消息,递增’attempt_number’值(它将为2)并将’retry_timestamp’值设置为now + 5分钟。消息克隆将再次发布到’retry__topic。
如果我们到达重试最高次数。现在是时候说“停止”了。我们将消息写入’failed_topic’并将此消息视为未处理。有人必须手动处理它。
服务如何做到高可用
服务如何做到高并发
首先,我们讲述了如何从0开始,将一个“草根项目”步步重构,最终打造为能抗住亿级流量的强悍系统。
亿级流量系统架构之如何支撑百亿级数据的存储与计算【石杉的架构笔记】
在支撑住了百亿量级的数据存储与计算后,新的问题又来了:系统架构如何避免单点故障?如何设计弹性计算资源调度机制?如何设计高容错机制?新一轮的重构,势在必行
亿级流量系统架构之如何设计高容错分布式计算系统【石杉的架构笔记】
还没完!随着业务的发展,系统将迎来百亿流量的高并发挑战,这时之前的那套架构就有些吃不消了。我们需要做计算与存储的分离、自研纯内存SQL计算引擎、对MQ做削峰以及流量控制、将系统重构为动静分离的架构。新一轮的重构,被业务的发展推上了风口浪尖!
亿级流量系统架构之如何设计承载百亿流量的高性能架构【石杉的架构笔记】
解决上述问题后,查询的问题又来了。我们如何设计能够支撑每秒数十万查询的高并发架构?新一轮重构,自研ElasticSearch+HBase+纯内存的查询引擎,彻底解决每秒10万查询的高并发挑战!
亿级流量系统架构之如何设计每秒十万查询的高并发架构【石杉的架构笔记】
最后,我们要确保设计出来的这套亿级流量架构的高可用!通过设计MQ集群高可用方案、KV集群高可用方案、实时计算链路高可用方案、冷热数据高可用方案、真正保证亿级流量架构全链路99.99%的高可用。
亿级流量系统架构之如何设计全链路99.99%高可用架构【石杉的架构笔记】
服务如何做到高性能
超高瞬时点赞 收藏如何解决
系统设计/架构设计面试题
系统/架构设计步骤
- 描述使用场景/用例,明确约束和假设
用例:系统有哪些功能
约束:限制条件,内存容量,高并发/s,
- 创建一个高层级的设计
画图:画出架构:画出主要的组件和连接
- 设计核心组件
对每个组件进行详细的分析
- 扩展设计
确认和处理瓶颈以及一些限制。举例来说就是你需要下面的这些来完成扩展性的议题吗?
- 负载均衡
- 水平扩展
- 缓存
- 数据库分片
论述可能的解决办法和代价。每件事情需要取舍。可以使用可扩展系统的设计原则来处理瓶颈。
如何设计一个秒杀系统
特点
逻辑简单,难点在于短时间有大量用户进来,短时频繁访问,因此,秒杀系统一定要满足:高并发,高可用,数据一致性

设计秒杀系统的过程中需要重点关注哪些问题
- 参与秒杀的商品属于热点数据,我们该如何处理热点数据?
- 商品的库存有限,在面对大量订单的情况下,如何解决超卖的问题?
- 如果系统用了消息队列,如何保证消息队列不丢失消息?
- 如何保证秒杀系统的高可用?
- 如何对项目进行压测?有哪些工具?
访问
有大量用户进来,短时频繁访问,如何处理热点数据呢,如秒杀url的获取,秒杀商品详情的获取
秒杀url - 动态化
- 在进行秒杀之前,先请求一个服务端地址,/getmiaoshaPath 这个地址,用来获取秒杀地址,传参为 商品id,在服务端生成随机数(MD5)作为pathId存入缓存,(缓存过期时间60s),然后将这个随机数返回给前端.
- 获得该pathid后,前端在用这个pathid拼接在Url上作为参数,去请求domiaosha服务
- 后端接收到这个pathid 参数,并且与缓存中的pathid 比较。如果通过比较,进行秒杀逻辑,如果不通过,抛出业务异常,非法请求。
https://www.cnblogs.com/myseries/p/11891132.html
秒杀商品详情获取
热点数据放在 Redis 中。最好写入到jvm 内存一份,jvm 内存中的数据访问速度是最快的
下单
下单时,会有大并发用户来下单,需要保证商品不超卖
下单请求太多
添加校验
使用回答问题或者弹出验证码限流
利用令牌桶、计数器算法实现应用级限流。
商品不少卖 - 高并发下怎么做余额扣减
将“实时扣库存”的行为上移到内存 Cache 中操作,内存 Cache 操作成功直接给 Server 返回成功,然后异步落 DB 持久化。
商品总量提前放入 redis 缓存中,让 redis 缓存扣减。redis 单进程,没有资源抢占问题。
库存移到redis缓存
1
2
3
4
5
6
7
8对应到代码层面,我们应该如何保证不会超卖呢?我们一般会提前将秒杀商品的信息放到缓存中去。我们可以通过 Redis 对库存进行原子操作。
伪代码如下:
Long count = redisTemplate.increment(key, -1);
if (count >= 0) {
......
}else{
......
}接口层 - 接口幂等
a. 分布式锁:Redis的Redisson。setNX(key)成功,则进行逻辑,然后删除del(key)
b. token机制:token机制的核心思想是为每一次操作生成一个唯一性的凭证,也就是token。一个token在操作的每一个阶段只有一次执行权,一旦执行成功则保存执行结果。对重复的请求,返回同一个结果。token机制的应用十分广泛。
c. db 唯一索引(建防重表):业务字段的唯一索性约束,防止重复数据产生
d. 乐观锁:业务字段的唯一索性约束,防止重复数据产生
e. 悲观锁:没有解决问题。不使用
什么是接口的幂等性,如何实现接口幂等性?一文搞定
高并发下如何保证接口的幂等性?
存储
使用缓存,定时写 DB
先放入redis中,定时写入DB,写入 DB 成功后,删除 redis中缓存
使用MQ(可选)
流量削峰用消息队列MQ
高可用
大批量请求来袭,服务如何承受
集群化
限流
限流是从用户访问压力的角度来考虑如何应对系统故障。限流是为了对服务端的接口接受请求的频率进行限制,防止服务挂掉。线程组件:Sentinel 、Hystrix等❶ 客户端限流
❷ 服务端限流
❸ 应用层限流:利用令牌桶、计数器算法实现应用级限流。排队
你可以把排队看作是限流的一个变种。限流是直接拒绝了用户的请求,而排队则是让用户等待一定的时间(类比现实世界的排队)。降级
降级是从系统功能优先级的角度考虑如何应对系统故障。NOTE:降级的核心思想就是丢车保帅,优先保证核心业务熔断
熔断和降级是两个比较容易混淆的概念,两者的含义并不相同。降级的目的是应对系统自身的故障,而熔断的目的是应对当前系统依赖的外部系统或者第三方系统的故障。熔断可以防止因为秒杀交易影响到其他正常服务的提供:
举个例子: 秒杀功能位于服务 A 上,服务 A 上同时还有其他的一些功能比如商品管理。如果服务 A 上的商品管理接口响应非常慢的话,熔断调这个接口,使其他服务不能再请求服务 A上的商品管理这个接口,从而有效避免其他服务被拖慢甚至拖死
性能测试
上线之前压力测试是必不可少的。推荐 4个比较常用的性能测试工具:
Jmeter :Apache JMeter 是 JAVA 开发的性能测试工具。
LoadRunner:一款商业的性能测试工具。
Galtling :一款基于 Scala 开发的高性能服务器性能测试工具。
ab :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
参考:
https://xiaozhuanlan.com/topic/4918673052
https://gongfukangee.github.io/2019/06/09/SecondsKill/
短 URL 系统是怎么设计的?
其实真正问你的是如下:如何生成,如何存储,如何访问,以及如何高并发生成 与 如何高并发访问
如何生成
- 使用发号器
通过发号策略,给每一个过来的长地址,发一个号即可,小型系统直接用mysql的自增索引就搞定了。如果是大型应用,可以考虑各种分布式key-value系统做发号器。不停的自增就行了。第一个使用这个服务的人得到的短地址是http://xx.xx/0 第二个是 http://xx.xx/1 第11个是 http://xx.xx/a 第依次往后,相当于实现了一个62进制的自增字段即可。为啥用62进制呢,因为 6 位 62 进制数可表示 568 亿的数,应付长链转换绰绰有余
参见:https://www.zhihu.com/question/29270034
核心:短链接生成算法 ==》核心:全局唯一id生成(即分布式id),然后将 id 进行 62转码
所以,问题衍生到了如诶生成“全局唯一id生成(即分布式id)”了。
方案有Twitter Snowflake,redis redisAtomicLong,mysql自增,javaAddr
- Hash
有重复问题,但可以通过“重复时加入自定义字段” 或 使用布隆过滤器
重复时加入自定义字段: 查库,如果发现重复,尾部加入自定义字段,重新hash
使用布隆过滤器: 用所有生成的短网址构建布隆过滤器,当一个新的长链生成短链后,先将此短链在布隆过滤器中进行查找,如果不存在,说明 db 里不存在此短网址,可以保存
如何保证同一个长地址,每次转出来都是一样的短地址
上面的发号原理中,是不判断长地址是否已经转过的。也就是说用拿着百度首页地址来转,我给一个http://xx.xx/abc 过一段时间你再来转,我还会给你一个 http://xx.xx/xyz。这看起来挺不好的,但是不好在哪里呢?不好在不是一一对应,而一长对多短。这与我们完美主义的基因不符合,那么除此以外还有什么不对的地方?
有人说它浪费空间,这是对的。同一个长地址,产生多条短地址记录,这明显是浪费空间的。那么我们如何避免空间浪费,有人非常迅速的回答我,建立一个长对短的KV存储即可。嗯,听起来有理,但是。。。这个KV存储本身就是浪费大量空间。所以我们是在用空间换空间,而且貌似是在用大空间换小空间。真的划算吗?这个问题要考虑一下。当然,也不是没有办法解决,我们做不到真正的一一对应,那么打个折扣是不是可以搞定?这个问题的答案太多种,各有各招,我这就不说了。(由于实在太多人纠结这个问题,请见我最下方的更新)如何保证大并发高可用
(1) 发号器分段
上面设计看起来有一个单点,那就是发号器。如果做成分布式的,那么多节点要保持同步加1,多点同时写入,这个嘛,以CAP理论看,是不可能真正做到的。其实这个问题的解决非常简单,我们可以退一步考虑,我们是否可以实现两个发号器,一个发单号,一个发双号,这样就变单点为多点了?依次类推,我们可以实现1000个逻辑发号器,分别发尾号为0到999的号。每发一个号,每个发号器加1000,而不是加1。这些发号器独立工作,互不干扰即可。而且在实现上,也可以先是逻辑的,真的压力变大了,再拆分成独立的物理机器单元。1000个节点,估计对人类来说应该够用了。如果你真的还想更多,理论上也是可以的。
(2) 高并发访问DB查id
如果用 Mysql 自增 id 作为短链 ID,在高并发下,db 的写压力会很大,这种情况该怎么办呢。
考虑一下,一定要在用到的时候去生成 id 吗,是否可以提前生成这些自增 id ?
方案如下:
设计一个专门的发号表,每插入一条记录,为短链 id 预留 (主键 id 1000 - 999) 到 (主键 id 1000) 的号段,如下
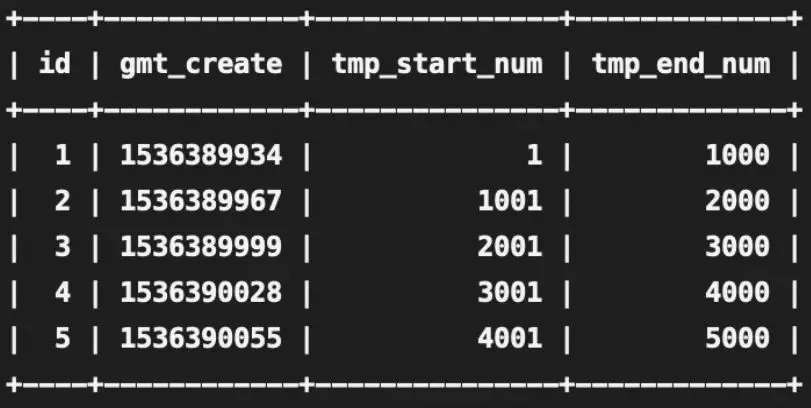
当长链转短链的请求打到某台机器时,先看这台机器是否分配了短链号段,未分配就往发号表插入一条记录,则这台机器将为短链分配范围在 tmp_start_num 到 tmp_end_num 之间的 id。从 tmp_start_num 开始分配,一直分配到 tmp_end_num,如果发号 id 达到了 tmp_end_num,说明这个区间段的 id 已经分配完了,则再往发号表插入一条记录就又获取了一个发号 id 区间。
转自链接:https://learnku.com/php/t/52596
如何存储
请求的的长链接作为KEY,生成的短链接作为value存储到DB中。
- 写入时高并发
如果用 Mysql 自增 id 作为短链 ID,在高并发下,db 的写压力会很大,这种情况该怎么办呢。考虑一下,一定要在用到的时候去生成 id 吗,是否可以提前生成这些自增 id ?
写入缓存:先存 redis,然后定时批量写入数据库
批量入库
如何访问
- 跳转用301还是302
这也是一个有意思的话题。首先当然考察一个候选人对301和302的理解。浏览器缓存机制的理解。然后是考察他的业务经验。301是永久重定向,302是临时重定向。短地址一经生成就不会变化,所以用301是符合http语义的。同时对服务器压力也会有一定减少。
但是如果使用了301,我们就无法统计到短地址被点击的次数了。而这个点击次数是一个非常有意思的大数据分析数据源。能够分析出的东西非常非常多。所以选择302虽然会增加服务器压力,但是我想是一个更好的选择。大概就是这样。
- 访问时高并发
(1)读写分离
这种系统显然,读远大于写。建议可以考虑做读写分离。
(2)引入缓存
假设,我们在一个时间。给手机推送短信链接的短信后。显然,后面的一段时间内,对该短链接的请求量会大大提升。没有必要每次都去数据库查询,因此可以引入redis缓存。
总结
核心:短链接生成算法 ==》核心:全局唯一id生成(即分布式id)
所以,问题衍生到了如诶生成“全局唯一id生成(即分布式id)”了。
方案有Twitter Snowflake,redis redisAtomicLong,mysql自增,javaAddr
链接:https://www.zhihu.com/question/29270034/answer/46446911
参考 https://www.cnblogs.com/myshowtime/p/16316654.html
整体设计参考:
https://learnku.com/php/t/52596
https://time.geekbang.org/column/article/80850
如何设计一个RPC系统
实现一个最基本的 RPC 框架应该至少包括下面几部分:
注册中心 :注册中心负责服务地址的注册与查找,相当于目录服务。
网络传输 :既然我们要调用远程的方法,就要发送网络请求来传递目标类和方法的信息以及方法的参数等数据到服务提供端。
序列化和反序列化 :要在网络传输数据就要涉及到序列化。
动态代理 :屏蔽程方法调用的底层细节。
负载均衡 : 避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题。
传输协议 :这个协议是客户端(服务消费方)和服务端(服务提供方)交流的基础。
讲的最好的rpc [RPC框架透彻解析:10个案例,30行代码纯手写一个RPC框架!马士兵]https://www.bilibili.com/video/BV1KG4y167n7?p=3&vd_source=c3e9801497e408c0e02a3ddb59c2d64e
[MyRPCFromZero-version1~6]https://github.com/he2121/MyRPCFromZero
[轻量级分布式 RPC 框架-黄勇-结合spring-文章](https://my.oschina.net/huangyong/blog/361751)
[轻量级分布式 RPC 框架-黄勇-结合spring-代码]https://gitee.com/huangyong/rpc
https://github.com/yaoyuanyy/guide-rpc-framework
https://github.com/Veal98/RPC-FromScratch
https://github.com/junjun888/simple-rpc
https://www.bilibili.com/video/BV1ZF411575U/?spm_id_from=333.788.recommend_more_video.0&vd_source=c3e9801497e408c0e02a3ddb59c2d64e
https://github.com/tomstillcoding/Simple-RPC
https://github.com/CN-GuoZiyang/My-RPC-Framework
https://github.com/search?q=My-RPC
架构心得
最后,分享一下做大型应用的架构心得:
灰度!灰度!灰度!
监控!监控!监控!
告警!告警!告警!
缓存!缓存!缓存!
限流!熔断!降级!
低耦合,高内聚!
避免单点,拥抱无状态!
评估!评估!评估!
压测!压测!压测!
原文地址:java技术栈知识点草集

